I’m running a lot of electrical meters in an residential area. Everything was running fine under v2. Now I moved the application to v3. The gateway is still connected to v2 cause physical access is quiet difficult and there is no remote access.
But with the forwarding from v2 to v3 it worked out of the box. Really cool!
Now after a few days the connection to a lot of meter broke and is not established again.
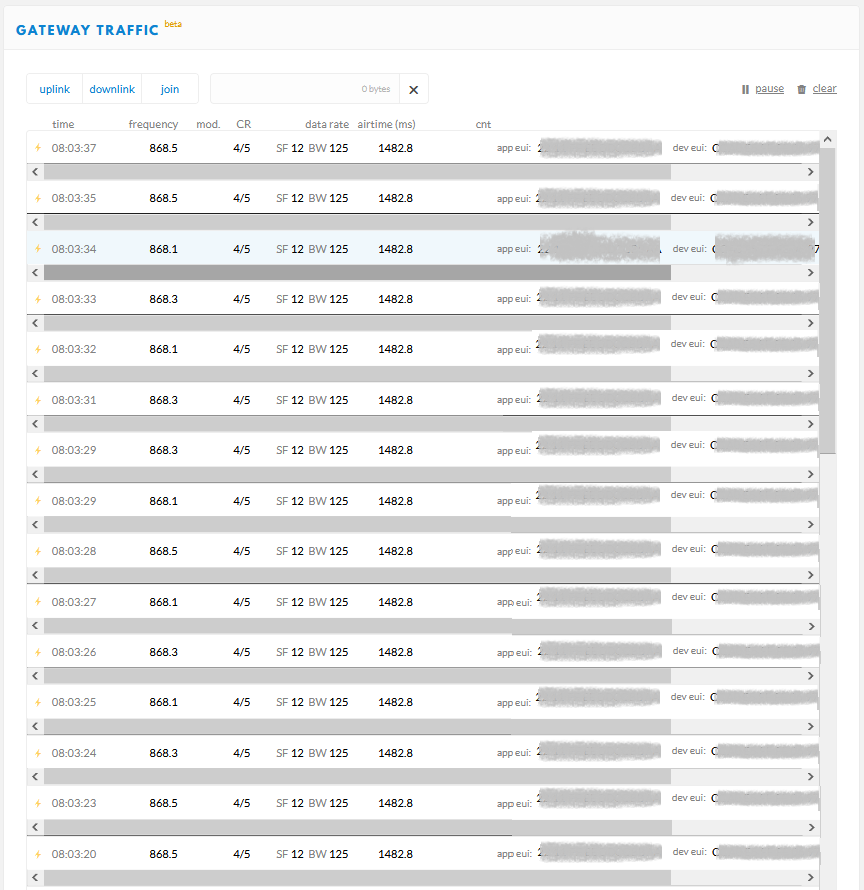
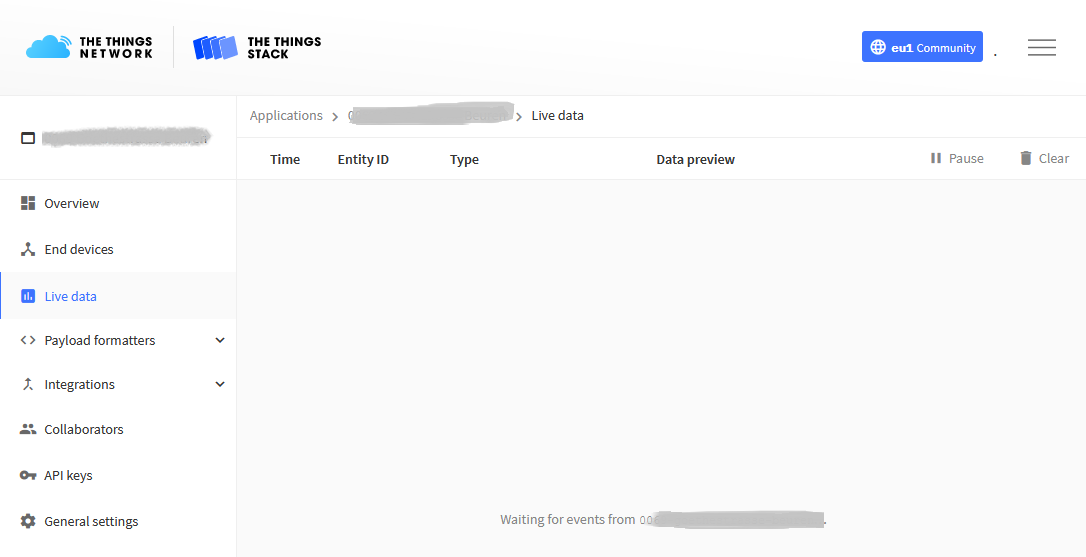
When I check the gateway in v2 I see a lot of join requests from different meters. But on the v3 application I see no traffic. Sometimes after a long time there is a lot of traffic but then nothing again for minutes.
Are there to many join request and v3 is blocking them in some way? Some kind of spam filter? The meters reboot and reconnect every day. But now none of them is able to join again.
So far there was never a problem, especially under v2. I created the v3 application 6 days ago and it was working fine as well. Yesterday afternoon/evening something “happened”.
Below you can see the received messages in my database. There was an almost constant flow of data before and suddenly it stopped.
I just realized the two test meters in my office stopped working 12 and 16 hours ago. Maybe it’s an general issue. Here I only have two meters. Nothing else. No other packages in the air.
I also encountered the same problem, everything worked until yesterday at 7pm CET.
I have a TTIG and it seems to no longer communicate with TTN v3. Maybe there are network problems in the V3 join server. My applications in V2 all work.
Possibly yes, Is that by design or just what is happening now? If by design that is poor practice. Are they all doing so at same time then hoping to connect, or have you ensured devices stagger their reboots and join requests? If not they may be interfering/ blocking each other/the gw in a cascade failure… Note GW is deaf to new join requests when txing join acks to previous requests forcing multiple retries, I see all SF12… 1.4 sec on air time with txs near overlapping albeit on just the 3 primary channels. Do they start at SF7 and have (gradually) moved to SF 12 after failing to connect or is that normal behaviour. Also doing so every day for how long? You may start to exhaust Dev Nonce for each device that way and if it’s not chosen at random start and incrementing NS will wait and refuse to allow join until truely new Dev Nonce used, meaning you might have a long wait whilst each device tries, fails then cycles through…though I would have expected the transition to V3 to clear that issues for a time.
TTIG not supported on TTN V3 for now so they never worked through that before! Also data will not pass through packet broker from a V3 Gw to a V2 app only the other way around hence we recommend migrating GWs to V3 last… once all V2 devices and apps in covered area migrated 1st…
There was an update cycle yesterday morning and there is currently a partial outage of PB affecting V2/V3 transfers https://status.thethings.network/
Normally they reboot at a random time, but about once per day, so there is no overlap of the join process. The only reason all meters start up at the same time is after a blackout, which is very very rare in this area. Normally less than once per year.
They start with SF7 and increase to SF12. They stay on SF12 for 4 packages. If there is still no join possible they switch back to SF7 and start increasing again. Also there is a delay between each transmissions.
I think the problem now is, they all rebooted by now and trying to join. But there is no answer from ttn. So they try it again and again. Not completely wrong. Would be better if the manufacturer would add a break after x tries and then wait for a longer time.
If I compare the curve in the end of this post, from https://status.thethings.network/, it looks really familiar to my database input in the initial post. So I think it’s definitely a general problem of the whole network.
I have also join problems since about 16h now. V2 gateway and V3 application.
My test node fails to join after a recompile where only a delay was made longer to get less packets…
Can you look at the application log in v3 to see if join accepts are being issued.
I find that some v3 devices aren’t able to hear or the gateway is able to process an OTAA join accept on a v2 gateway.
And as blunt as this is, you are definitely in the “early adopter” zone of TTN v3 so if you want a quiet life for the next few months, you may want to move your devices to v2.
Rejoining once a day is bad practice and burns join nonces. In ideal circumstances that will not be too big an issue as you have 64K available, but in case of network issues you are burning them like there is no tomorrow. A node can use confirmed uplinks to check connectivity a few times and if there is no response for X of them decide to rejoin. Rejoining every day is really not in line with LoRaWAN best practices.
Thanks for your respond, sounds absolutely logic. I will change it for my devices and will talk to the supplier as well. Maybe they change it, so that other people who use it out of the box don’t have the same setup.
there is an open issue about the packet broker between v2 and v3 — we have same problems of v3devices since yesterday in the early evening. they are sending data through a nearby v2 gateways, they run through the v2 gateway console but get lost on the forwarding path to v3 ---- no more dataflow here, no logs in the v3 console, no online devices… open issue — thanks to the team thats investigating !
V2 will become read only in about 1 month. A testing phase of a few months seems rather normal for remote placed equipment, so “early adopter” is not something you expect in the last month before the previous version becomes read only.
It may be going read-only in 1 month, but that doesn’t stop you being an early adopter, particularly for double digit number of devices. There are many many posts here of people finding their way on moving devices so it’s more an art than a science at present.
I’m following the Abraham Lincoln route: “Give me six hours to chop down a tree and I will spend the first four sharpening the axe”
Did you move two or three devices or all 75 in one go?
I transferred all 75 at once. Exporting all devices with the ttn command line tool and adding them with the ttn v3 wizard/batch/whatever function. The job was done in 5 minutes.
I was not expecting a fully functional system. I tried it before with a single test device btw.
I just wanted to see if it works out fine. And for 5 days it was working perfectly. Let’s wait for the fix.
Sounds like a good scheme - it’s so hard to tell from all the various details that get discussed and with all the different types of devices I have I’m struggling some days to figure out if it’s the device, me or v3 - sometimes a combination of two or all three.
As I’m trying to figure out why OTAA join accepts don’t appear to be going through two of my test gateways on v2, I don’t know if that’s a general issue or specific to them. All the while trying to do some actual work!
Can you deploy a v3 gateway as a temporary solution?
nothing - wait and keep calm until the team has found the cause ---- if you are in hurry just downgrade your devices back to v2 and they will run as before i guess