Let me try to sum everything up as i read again my emails with Sensoterra, this thread and PMs we had with @descartes. As putting pieces together helps me understand a bit more, it may be helpful for others people too.
We bought 8 Sensoterra soil moisture probes. These probes come already registered to TTN by Sensoterra so we just have to wake them up for them to start joining and sending packets through TTN to an endpoint managed by Sensoterra, that performs raw data treatment (soil-specific recalibration done on the server side), displaying of the data and API integration for delivery and subsequent use of this cleaned data. The probes are enclosed and autonomous, and come with a battery that is supposed to last at least 3 years.
This particular design implies that…
In order to provide connectivity, we bought a TTIG gateway that is powered via a solar panel setup, and a 4G dongle ensures the wifi backhaul. We tested everything beforehand in the office, and have a way to remotely monitor that everything is powered up and connected to the internet.
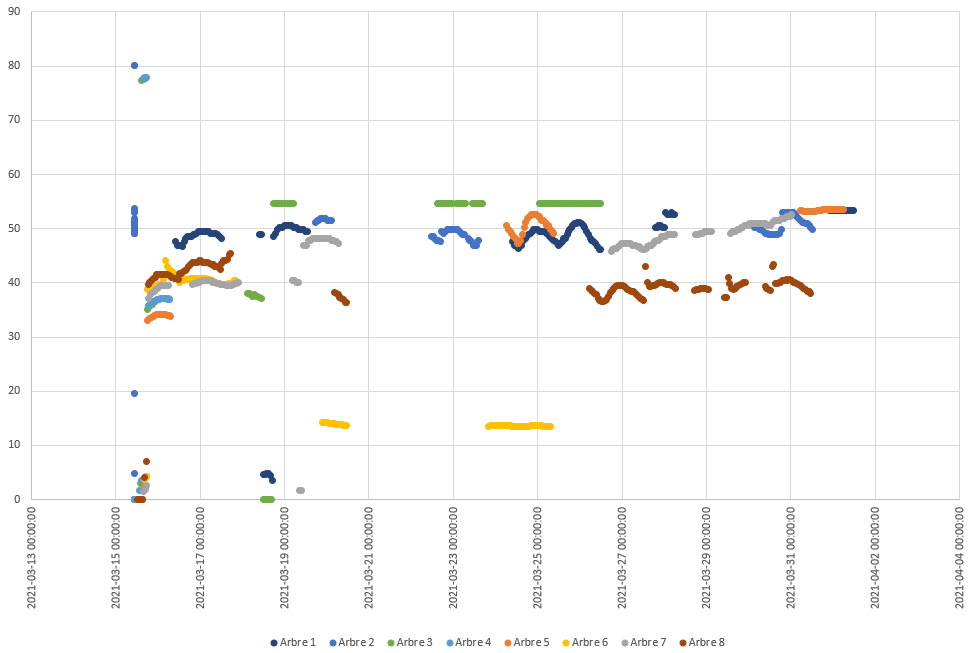
Now, this setup has been installed mid-march in a citrus orchard with the following layout, with the TTIG being installed in Arbre 1 at 2m high and all probes being installed at ground level. Max distance between the TTIG and the probes is ~100m. Declared signal strength in console ranges from 9+/-1 for SNR, -105+/-5 for RSSI.
When we installed the whole setup, all the probes showed up in Sensoterra’s interface, meaning that they successfully performed at least a join and an uplink. Later on, some randomly stopped sending data, while other started sending again. For info these probes have a cache of 6 measurements and each time send a packet with a “trail” of the 6 last measured values. The data is collected hourly in normal mode and once a day in stock mode. The sensors store up to the last six measured data points, so for normal mode up-to 6 hours and in stock mode up to 6 days. Chart of the points logged by Sensoterra’s server during the past 15 days below :
Just to be clear, I understand you have the TTIG on the free to use TTN v2 console and that you see traffic on the TTIG’s console?
After that, yes, we decided to have a look at the TTN monitor to try to understand what was going on. Here’s an example of what we see (html file). We registered the TTIG on TTN console and started monitoring. We noticed that we are receiving a high number of join requests, followed by join accept, without consistent up/downlinks. It is around this time that we started discussing with the Sensoterra team, posting this thread, and discussing in PM with @descartes.
First, gateway placement and RF attenuation issues were ruled out based on Sensoterra’s experience as signal strength of the sensors was checked and the values did not seem out of the ordinary. This is going on the opposite direction from @Jeff-UK’s posts :
Then, discussion focused on putative packet forwarder issues, probably based on the miscomprehension between TTI and TTIG.
Meanwhile, discussion in this thread and in PM with @descartes evoked the join issues :
After phone discussion with Sensoterra we had confirmation that the sensors perform a new join request every 24h when they are not able to reach the gateway after 6 to 8 tries.
At some point, Sensoterra understood we were working with TTIG router and not a router connected to TTI, as well as the fact that the TTIG is so straightforward that it does not allow any endpoint to be redefined manually. They then kind of switched onto blaming the device itself.
To which @descartes took again some time to explain to me in PM :
Sensoterra them then added observations about putative timing issues of the TTIG :
As mine is still in 2.0.0, i also went to check if these kind of issues were solvable with the last TTIG firmware, but according to the community the issues we’re facing do not seem to be fixable by that.
Last, Sensoterra team suggested to try to keep the port socket open. I read some topics mentioning “keep awake” issues and some workarounds for TTIG as having a beacon node that is here for the sole purpose of maintaining an active connection (from what i understood this is what you call a canary, right ?). This seemed to help some people having trouble with TTIG around here, still as it wasn’t proposed in this topic i guess this may not be that relevant. Still, as we probably won’t be able to do anything on the Sensoterra probe side, do you think it could be a viable workaround to be able to use TTIG nevertheless ?
In any case, we ended up ordering a RAK gateway in order to do some troubleshooting ; thing is with the new french lockdown time will fly until the day we get it and bring it to the orchard !..