They don’t need access. The devices are registered by the manufacturer on TTN before shipping. So the user gets themselves a TTN gateway and it all joins up. The uplinks are relayed on to the manufacturers dashboard / back-end and when you ‘register’ your sensor it shows you its info.
Feel free to ventilate on the pitfalls in this cockamamie scheme but if you are a tree planter / hugger and just need some water sensors for your orchard, you’d not know any better until you come here for help.
They do need access. Somehow they logged in or subscribed to the data - are they using an account the vendor created after registering devices in it, or what?
There are steps someone had to do, the question is how those got done before the asker got their hands on the result, and by extension if they got done right.
The question that was ignored was “Where did the account / login you are using to access these come from?”
It was generated by the probe manufacturer shortly after we ordered them, hence the “we just turned the gateway on, shook the device to wake it up and data was forwarded for some time”.
The consequence is that there are details of the setup in TTN (not to mention the behavior of the node itself) which only the vendor really knows. And they’re not standing there helping you through the process.
Worse they’ve set you up in a version of the system scheduled to be turned off later this year, and made promises they were in no position to honor about how long something they have no role in maintaining would stay available.
You probably need to have some stern words with the vendor and get them to stand behind what they’ve offered to you, or at least make enough technical detail of it available to you that you can be self-supporting with the aid of ordinary community resources not having to guess at what your vendor was thinking.
No they don’t. They absolutely do not need to log in to setup a device or even log in to an account setup for them. I can provision a device right now and send it to someone with a gateway and pipe the uplinks to them without them having any access to the application or the device. If there is a gateway near by we can rely on, they don’t even need their own gateway.
I know this because I’ve done this a couple of times - customer needs battery level, customer gets email each morning with battery level, customer happy.
Yes, I know which one was ignored. But it doesn’t apply. The customer doesn’t get access to the application console. Period. Because as I said above, it’s all done by the manufacturer before the devices are shipped. And mostly they seem to be able to do this properly otherwise they wouldn’t really have a business.
The customer gets access to an online dashboard / portal that the manufacturer provides that gets the data from TTN, processes and presents it.
Whilst we know it would be preferable to see what’s going on at device level, that’s not the deal on offer.
If you go down that path then you are responsible for making it work, since you’ve made it impossible for the customer to help themselves, or for the community to help them.
Such a customer can gain nothing by posting here.
But this customer actually does have a login to get to a TTN console view.
@cslorabox, moving this on in a direction we have some control over, any thoughts on a low cost gateway so @codename5281 can have something else for general testing & getting to grips with LoRaWAN.
Well, we are trying to get them up to speed on the constraints of the offering they purchased and trying to get some other kit to help with trouble shooting …
IMHO debugging best starts by understanding the design of the node, and seeing what it’s doing - debug output is both cheaper and more informative than a gateway.
Seems like the real problem is that the system falls into the gap between something designed to be maintainable, and something actively supported by the vendor so that the customer doesn’t need to bother understanding the details. This is a no-information, no-support pitfall.
One can buy an open architecture gateway like something with a proper multichannel concentrator card based on a pi (great for office based testing, not so good for field deployment) but actual problems may not be understandable or solvable without engineering-level access to the node behavior.
But getting hold of a Pi based gateway as suggested:
will allow some back in the office testing with both on the gateway as well as console logs to get in to the detail of what’s happening with spontaneous re-joins.
And in parallel, liaise with Sensoterra about resolving both the immediate issue of the devices not working and the medium term issue of who holds the keys to the kingdom.
In the meanwhile, Mistress Google will penalise them because this thread will rank well and I’m not sure it will be what they want discussing in public. But that’s a problem they generated.
Not a great recipe for success I’m afraid… it will work but not very efficiently and you will throw away a lot of the range and penetration benefit of LoRa in that case. Your deployment is typical of soil sensors and others where device deployment is at or close to ground level … or even below (think water meters in pits!). Ideally you should try to get the sensor ant up at >>1m and the gw much higher… early LoRa proving tests for the water industry had devices in pits - often in concrete collars and with metal lids over the top…but the GW’s were typically on top of e.g. Parisian tower blocks! If nodes are low the GW’s really need to be high to subtend a decent tx angle… you really need to read up on e.g Fresnel zone… you will probably be loosing >40% of your radiated energy…and that is before allowing for any obstructions or any ground/terrain masking as you look to scale out.
That said the TTIG is a nice low power device and if rehoused and/or adapted to implement an external antenna (helps in gaining height if run of a short length of ultra low loss cable) and partnered with a close by WiFi back haul or connected over WiFi to a low power 3G/4G dongle you have a great starting point for a solar solution, depending on tolerance for power outages, desired panel, or battery capacity, geo location (how much thermonuclear energy you can harvest!) and if full day sun or partial shadow/obscured.
Would agree with Nick that
Would be a good move until you can reliably test and easily add new devices reliably and consistently… then move to field deployments. Buy yourself a telescopic 8 or 10m or even 15m Ariel mast and put ant (& gw?) at top then tether with guy ropes to start your field test… 2m might as well be on a table top in this scenario
Also just to add my 2penneth on customer deployments, unlike typical ttn forum users and even some on this thread many are not into the details but only interested in the final solution/result and don’t give two hoots about device details, gw complexities, secret sauce or secret keys…they just want something that is easy to deploy or that can be deployed for them, powers up and works with a nice dashboard display or some graphs, perhaps with some kind of historic data storage for review and/or analysis or audit… in which case pre configuring and shipping a (set of) device(s) to connect to a network, with a (again pre configured if needed) low cost gw, possibly remotely managed, if they are not already in range of one, with the actual data - the only bit they really value or are interested in - then presented on e.g. a simple shared project Cayenne link they can open on a pc, tablet or even their phone. So can understand why some kit suppliers go that route and can see why Nick has clients in same mode, as have a few like that myself.
As for
I would happily carry his bags and besides orchard ok as though a wine fan like Nick I also appreciate cider/cidre/scrumpy… and Limoncello …so not fussy really
Let me try to sum everything up as i read again my emails with Sensoterra, this thread and PMs we had with @descartes. As putting pieces together helps me understand a bit more, it may be helpful for others people too.
We bought 8 Sensoterra soil moisture probes. These probes come already registered to TTN by Sensoterra so we just have to wake them up for them to start joining and sending packets through TTN to an endpoint managed by Sensoterra, that performs raw data treatment (soil-specific recalibration done on the server side), displaying of the data and API integration for delivery and subsequent use of this cleaned data. The probes are enclosed and autonomous, and come with a battery that is supposed to last at least 3 years.
This particular design implies that…
In order to provide connectivity, we bought a TTIG gateway that is powered via a solar panel setup, and a 4G dongle ensures the wifi backhaul. We tested everything beforehand in the office, and have a way to remotely monitor that everything is powered up and connected to the internet.
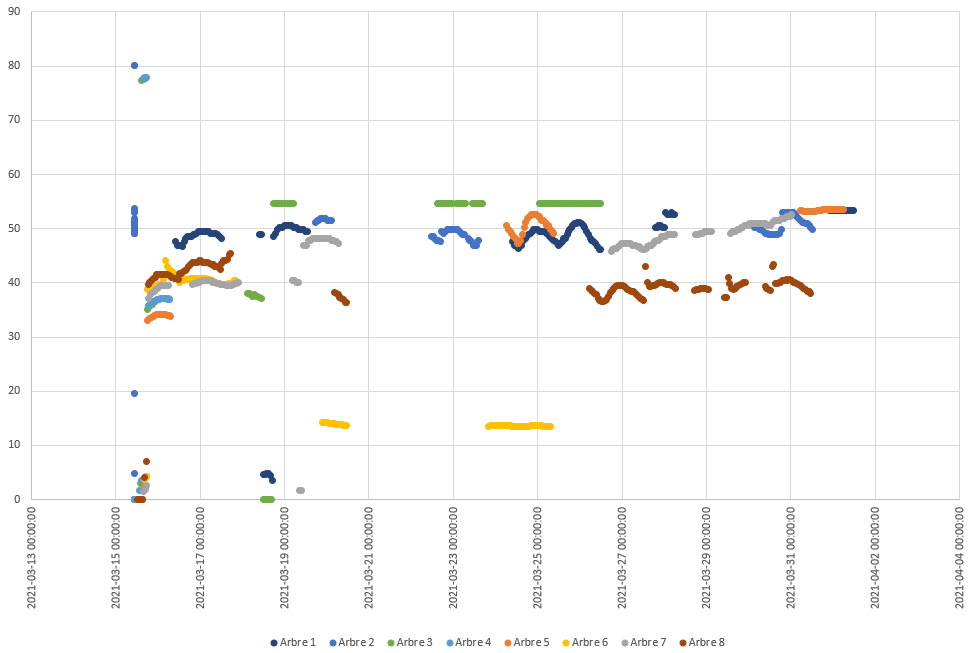
Now, this setup has been installed mid-march in a citrus orchard with the following layout, with the TTIG being installed in Arbre 1 at 2m high and all probes being installed at ground level. Max distance between the TTIG and the probes is ~100m. Declared signal strength in console ranges from 9+/-1 for SNR, -105+/-5 for RSSI.
When we installed the whole setup, all the probes showed up in Sensoterra’s interface, meaning that they successfully performed at least a join and an uplink. Later on, some randomly stopped sending data, while other started sending again. For info these probes have a cache of 6 measurements and each time send a packet with a “trail” of the 6 last measured values. The data is collected hourly in normal mode and once a day in stock mode. The sensors store up to the last six measured data points, so for normal mode up-to 6 hours and in stock mode up to 6 days. Chart of the points logged by Sensoterra’s server during the past 15 days below :
Just to be clear, I understand you have the TTIG on the free to use TTN v2 console and that you see traffic on the TTIG’s console?
After that, yes, we decided to have a look at the TTN monitor to try to understand what was going on. Here’s an example of what we see (html file). We registered the TTIG on TTN console and started monitoring. We noticed that we are receiving a high number of join requests, followed by join accept, without consistent up/downlinks. It is around this time that we started discussing with the Sensoterra team, posting this thread, and discussing in PM with @descartes.
First, gateway placement and RF attenuation issues were ruled out based on Sensoterra’s experience as signal strength of the sensors was checked and the values did not seem out of the ordinary. This is going on the opposite direction from @Jeff-UK’s posts :
Then, discussion focused on putative packet forwarder issues, probably based on the miscomprehension between TTI and TTIG.
Meanwhile, discussion in this thread and in PM with @descartes evoked the join issues :
After phone discussion with Sensoterra we had confirmation that the sensors perform a new join request every 24h when they are not able to reach the gateway after 6 to 8 tries.
At some point, Sensoterra understood we were working with TTIG router and not a router connected to TTI, as well as the fact that the TTIG is so straightforward that it does not allow any endpoint to be redefined manually. They then kind of switched onto blaming the device itself.
To which @descartes took again some time to explain to me in PM :
Sensoterra them then added observations about putative timing issues of the TTIG :
As mine is still in 2.0.0, i also went to check if these kind of issues were solvable with the last TTIG firmware, but according to the community the issues we’re facing do not seem to be fixable by that.
Last, Sensoterra team suggested to try to keep the port socket open. I read some topics mentioning “keep awake” issues and some workarounds for TTIG as having a beacon node that is here for the sole purpose of maintaining an active connection (from what i understood this is what you call a canary, right ?). This seemed to help some people having trouble with TTIG around here, still as it wasn’t proposed in this topic i guess this may not be that relevant. Still, as we probably won’t be able to do anything on the Sensoterra probe side, do you think it could be a viable workaround to be able to use TTIG nevertheless ?
In any case, we ended up ordering a RAK gateway in order to do some troubleshooting ; thing is with the new french lockdown time will fly until the day we get it and bring it to the orchard !..
Realistically, while your vendor is right about TTIG issues, if they don’t give you technical details of their devices behavior, it’s on them to solve this.
They can’t expect the community to debug proprietary products.
My firm rule is not to by things which are not user serviceable - that rules out both your node vendor, and also the closed TTIG.
Just a couple of quick comments on this - appreciate the write up and fact you have reported back
re #6 - Yes deploy a Canary node - always good to have another device of a type that is not being used as part of a sensor ‘monoculture’ - even if just a simple T&H monitor - will have addded value of reporting ambiant conditions and warn of e.g. frost that might affect yields. Set it up at ~same 2m height as GW - perhaps in one of the trees with LOS to GW placed min 25/30m away, better yet 50-250m away - set for low power and short SF (7) so that on air time is minimal (enable ADR?) on a 5-10 min reporting cycle - this will help keep Websockets connnection responsive and remove Sensoterra excuses If you dont want to build something yourself simply grab a Laird RS186 or Dragino LHT65 - will do a fine job with longish battery life and reliable operation. As noted this will keep the Websockets connection operational and responsive.
There were early TTIG problems - widely reported and commented on on the forum and whilst Sensoterra are right to call these out the fact is with improvements to back end and improvements to TTIG f/w this is generally no longer an issue - as they should know - and its a bit naughty of them to try and point finger that way.
Your RAK GW should also work fine in this type of deployment and will help provide redundancy and extra coverage if deployed as an additional item vs replacement.
Re
That is indeed self evident in what you are seeing. You hadnt mentioned max 100m range earlier - that should be fine but you ARE wasting LoRa benefits as shown by your signal data:
Declared signal strength in console ranges from 9+/-1 for SNR, -105+/-5 for RSSI.
This is the kind of RSSI/SNR typically seen from nodes several km away not <100m! Your close range tests are running fine but what happens when you scale out to the next field/orchard say 300m away or down the valley say 1.5-2km away?! Your solution (specifically the lack of height for GW) will not scale and as I noted is very inefficient wrt LoRa usage. At the moment I would expect to see RSSI’s from aro -65dbm to -85dbm for current config and remember 6db represents approx doubling of range that can be achieved - it is in the nature of the devices that they have to be in/close to ground - that cant be helped but you can help yourself by getting the GW higher to minimise/mitigate the Fresnel effects. Please try when free from lockdown
4G ‘should be ok’ for backhaul unless your network is way out on a limb and hopping through many repeaters or long fibre or dsl back hauls to RAN and Cellco central office.
Re Sensoterra timing and tight coupling to their own back end - sounds like marginal LoRaWAN performance - are they LA certified devices? (I havent checked), if so that should be no excuse - and may be its part of a vendor lock in strategy - even if inadvertent! Which is a pity as like the look of their units and was impressed when I saw them launched - was thinking of getting a few to evaluate for possible client deployments but your story puts me off somewhat (not good PR for them )
If anyone from Sensoterra is reading this perhaps they want to throw a couple of units to Nick (@descartes ) and myself to abuse and destroy - sorry I mean to test and evaluate, potentially against a range of GW’s and backhaul solutions - so we are in a better position to judge and advise!..
The console log is very useful. A quick scan of it reveals a number of issues. Can someone transcribe it with columns of:
Time, Msg Type, DevAddr, DevEUI, SF
Where Type = JR, JA, Up, Dn
so we can dig in to the detail. Some sensors happily make it in to double figures for uplinks. The first entry (at the bottom) indicates one is far too close to the TTIG and is overloading the TTIGs RF input stage, that’s a newbie error, but irrelevant, it joins eventually, question is, does it re-join at a later point.
Shame we don’t know what each sensors DevEUI is so we can place it on the map.
Question to this is how do the sensors decide that they are not able to reach the gateway - do they send confirmed uplinks (so the Network Server commands the gateway to transmit an Ack) or do they rely on a downlink from the Sensoterra back end to confirm that data is flowing.
Jeff Mckeown was around at the time they launched LoRa. He’s deployed dozens of community gateways around the UK. If anyone was going to know about gateway’s, it’s Jeff. Or Jac Kersing. Or LoRaTracker. All do RF & antennas, me, not so much, I’m more firmware, devices and business intelligence (data processing).
This was a total red herring - it actually says in the link it’s not used by TTI, it was created for other gateways that want to connect to TTN. And the TTIG uses BasicStation. This sort of commentary from Sensoterra is just fishing for a reason.
Having seen some gateway logs, I wonder why the Sensoterra back end is not going berserk with alerts about all the re-joins - I assume you don’t get any emails saying your deployed sensors aren’t happy??
Is there anyway of getting hold of one - anyone out in Morocco that can pull one out the ground and send it north? Positioning the sensor & a TTIG for experimentation would be good.
Do you have pictures of the TTIG in it’s weather proof box - how the antenna was extended out of it would be useful knowledge to help with elimination of any other spurious objections from Sensoterra.
Just took a quick scrolling look through the console data you shared (havent done any detailed analysis) but from what I see I note a lot of uplinks are SF9-SF12 (ignoring the Join reqs gradually ramping up in SF when unsucessful?), where for this range I would expect to see neary all SF7 or SF8. Also many (most?) uplinks are quickly followed by a downlink suggesting the packets are being sent ‘confirmed’? Not a good practice and generally frowned upon as a) as you burn through GW dutycycle limts - again reducing ability to scale, b) potentially will breach TTN FUP very quickly (Max 10 downlinks per day inc join process and acks!), c) when txing a downlink (or repeated join accepts for that matter if node doesnt catch and action forcing repeats) the GW is unable to listen for uplinks - it goes deaf! …and that might result in gaps in Rx data…just saying
As Nick asks please log more & bin the data and if/when I get 5 I may have a browse through…
@Jeff-UK, Sensoterra have closed firmware that the management do not appear to be able to describe the general scheme of operation and the sensors are registered on a private TTI instance that the customers don’t have access to - all they see is what appears on the Sensoterra dashboard. There is no evidence there is a device management system in place, otherwise the re-joins would have been identified by them long before the user did.
So whilst the observations are correct, this is all down to Sensoterra.