Hi,
I’m wondering if anyone has had any issues with secondary LoRaWAN ports not coming across TTN correctly. In my current setup, I’m using LMIC to broadcast short status messages on Port 2 that consist of 8 flags in the form of a bitmap. Here is what the code looks like:
void send_status() {
uint8_t txBuffer[1];
LoraEncoder encoder(txBuffer);
encoder.writeBitmap( _BME280_found,
gps_available(),
_ssd1306_found,
_axp192_found,
_ifWebOpen,
_ifSetMiner,
_ifAuthenticated,
_ifLaunched );
// Battery / solar voltage
//encoder.writeUint8(0);
boolean confirmed = false;
ttn_cnt(_count);
Serial.println("Sending balloon status message.");
ttn_send(txBuffer, sizeof(txBuffer), 2, confirmed);
_count++;
}
where ttn_send is written like this:
void ttn_send(uint8_t * data, uint8_t data_size, uint8_t port, bool confirmed){
// Check if there is not a current TX/RX job running
if (LMIC.opmode & OP_TXRXPEND) {
_ttn_callback(EV_PENDING);
return;
}
// Prepare upstream data transmission at the next possible time.
// Parameters are port, data, length, confirmed
LMIC_setTxData2(port, data, data_size, confirmed ? 1 : 0);
_ttn_callback(EV_QUEUED);
}
About one minute after startup, I’m broadcasting observation messages on Port 1 that consist of temperature, pressure, humidity, GPS coordinates and including the same bitmap byte normally used in the status messages. These messages come across just fine and here you can see I’m using the LMIC library the same way.
void send_observation() {
//LoraMessage message;
uint8_t txBuffer[31];
LoraEncoder encoder(txBuffer);
encoder.writeLatLng( gps_latitude(), gps_longitude() );
encoder.writeUint16( gps_altitude() );
encoder.writeRawFloat( gps_hdop() );
encoder.writeUint16( (uint16_t)_elevation_now ); // In meters
encoder.writeUint16( (uint16_t)(_pressure_now*10.0) ); // Convert hpa to deci-paschals
encoder.writeTemperature(_temperature_now);
encoder.writeHumidity(_humidity_now);
encoder.writeBytes( _launch_id, 8 ); // Add 8 bytes for the launch_id
encoder.writeBitmap( _BME280_found,
gps_available(),
_ssd1306_found,
_axp192_found,
_ifWebOpen,
_ifSetMiner,
_ifAuthenticated,
_ifLaunched );
Serial.println("Built message successfully");
// LORAWAN_CONFIRMED_EVERY is defined in a configuration file as 0
#if LORAWAN_CONFIRMED_EVERY > 0
bool confirmed = (_count % LORAWAN_CONFIRMED_EVERY == 0);
#else
bool confirmed = false;
#endif
ttn_cnt(_count);
Serial.println("Sending balloon observation message.");
ttn_send(txBuffer, sizeof(txBuffer), 1, confirmed);
_count++;
}
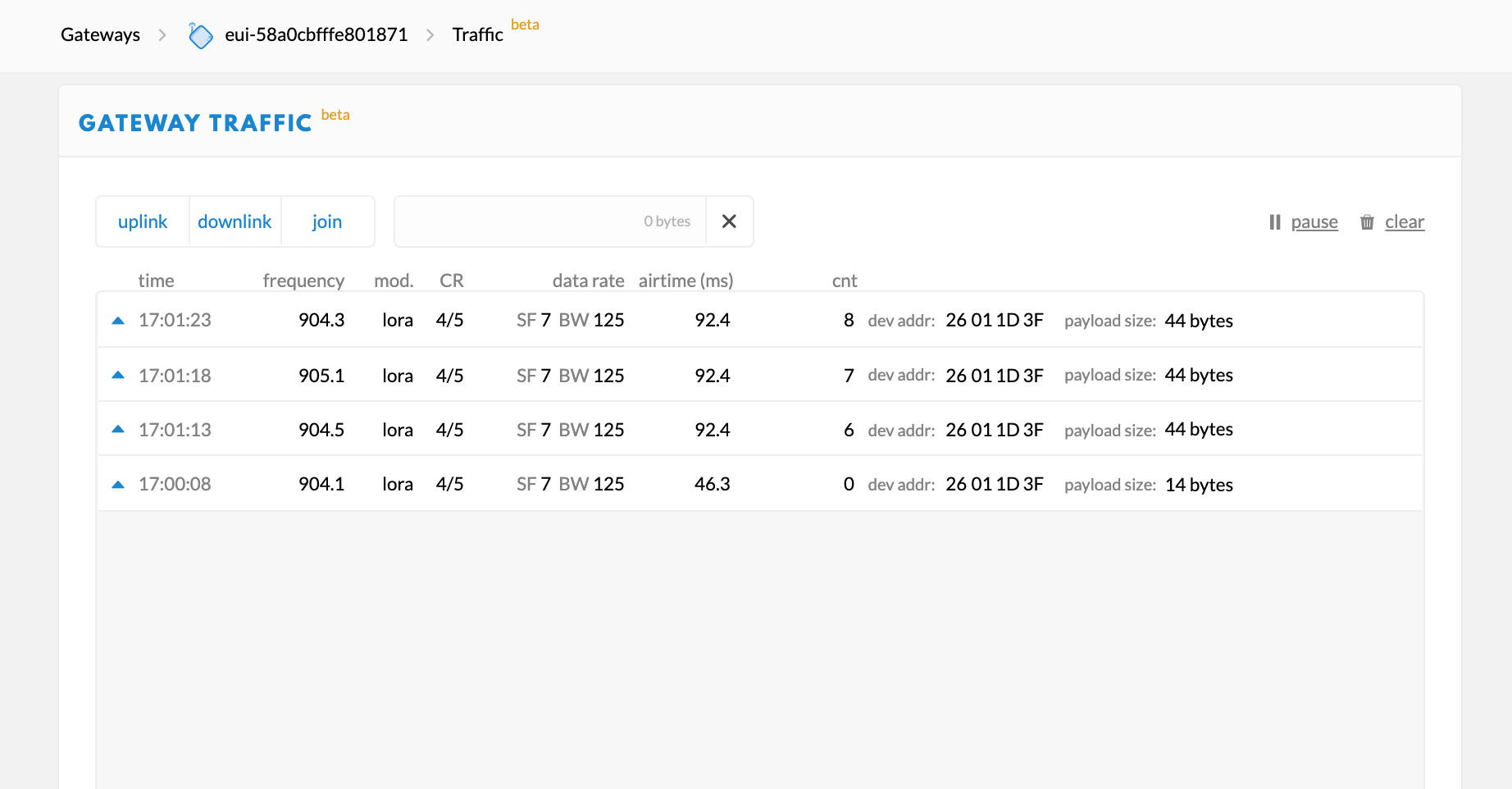
The very first Port 2 Status message gets received by the gateway, but the following 5 are discarded (counts 2,3,4,5 in the picture), even if the subsequent flags are changed (payload is different). Interesting that the first Status message includes is annotated with “Retry” by TTN. The Port 1 Observation messages, however, come across just fine… in the picture you can ignore the empty byte 00s , as it’s just because Lat/Lon fields haven’t been populated by that time.
I’m using a TTGO T-beam V1.1 with the LMIC library to send the messages and a 915mhz TTN Indoor gateway to receive the data. I’m forwarding to ttn-handler-eu. I’m wondering if there’s any obscure fact that I’m missing. My hunch is that the LMIC library isn’t clearing out a cache or something to that effect. Or perhaps the TTIG gateway isn’t forwarding correctly to the TTN eu server?
Has anyone seen these port issues before?
Nick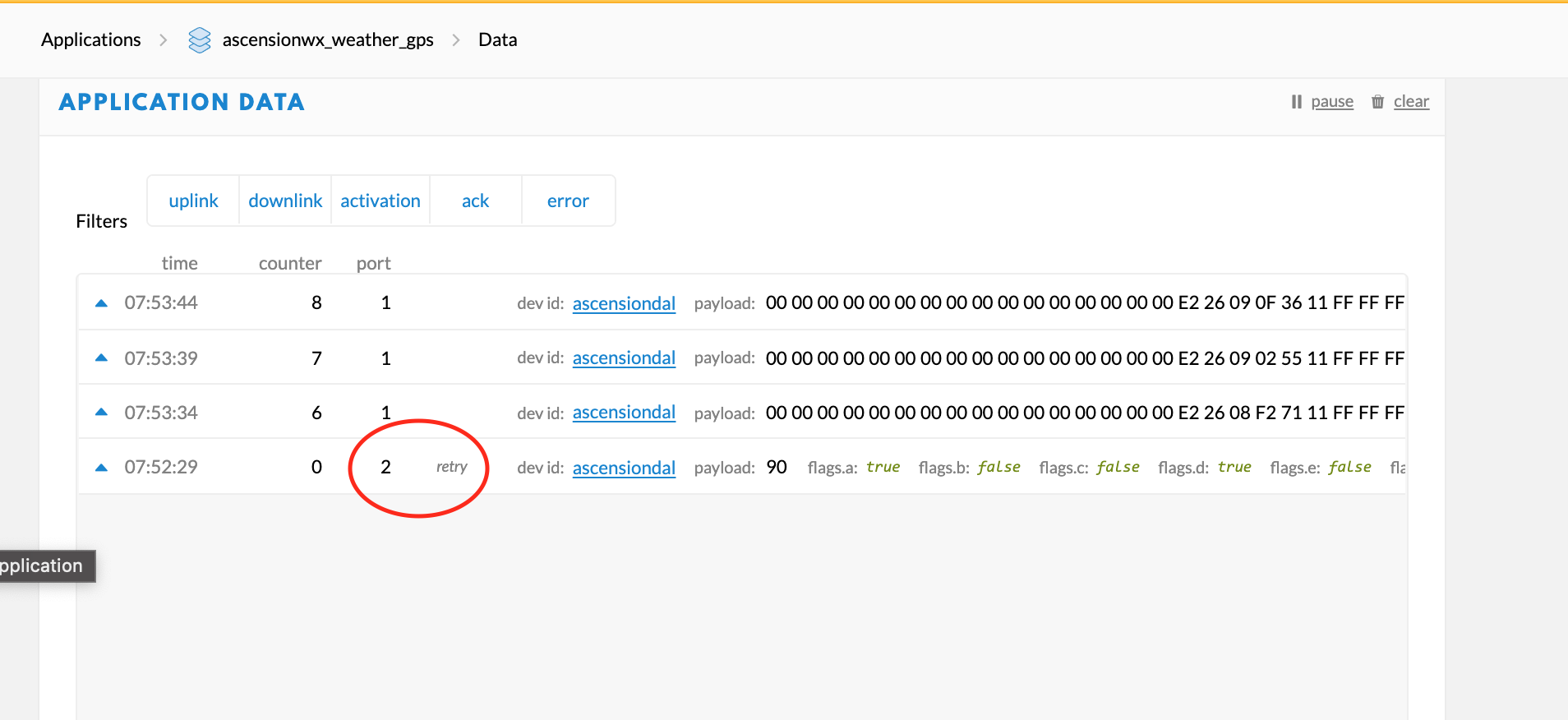
 as Nick and Chris said you need to back it down whatever…
as Nick and Chris said you need to back it down whatever…