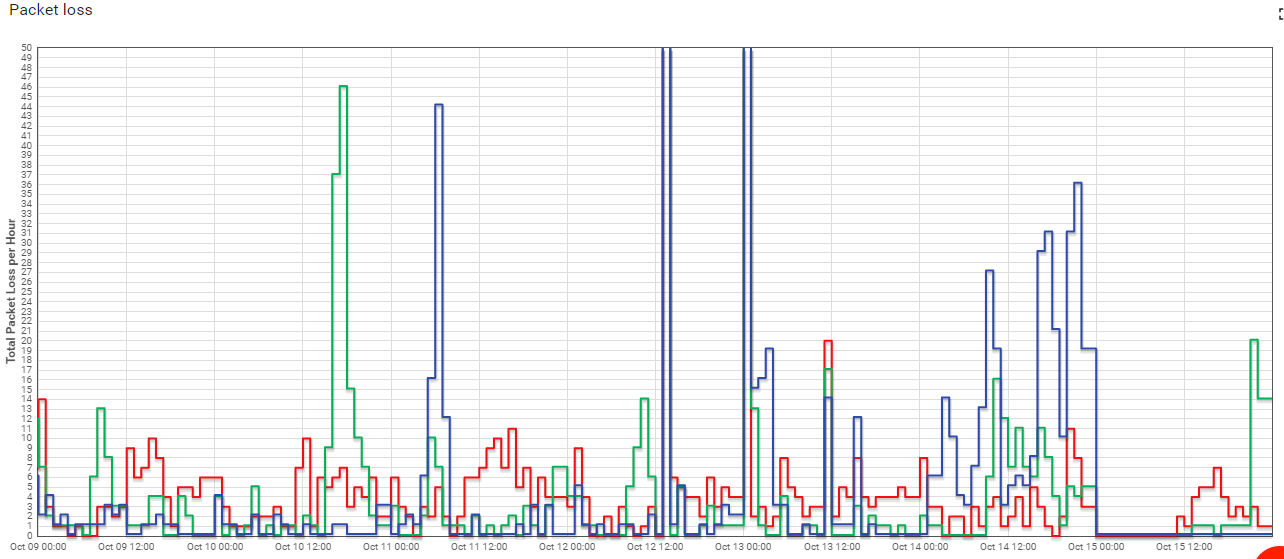
We are about to set up a larger lora network based on TTN. During the past few weeks we have monitored the packet losses of our test bench. This are the hourly packets lost:
The issue had been discussed before, but I have a different question.
One option we are thinking about was to move to a (paid) private network, which could be a solution.
BUT: With a private network, nobody can benefit from our gateways (and vice versa). We generally like the idea of a free and public network, so moving all commercial projects out of TTN might be not the right way.
So, we would more like to support TTN in a way, that the network will be more reliable in the future. As you see, the loss rate is relatively low most of the time. It seems, that the whole network sometimes is down for 30 minutes or more.
So, here are my questions:
a) does anybody know the reasons for longer downtimes of the backend?
b) how to support the network?
This is exactly why TTN needs to support sharing of gateways to which it will not have exclusive access, by implementing a scheme to indicate when a gateway is (as a result of obligations to its owner’s network server) unable to handle a transmit request and TTN should instead assign it to any other gateway that might be in range.
People such as you who invest in putting up gateways because they need their data can’t risk losing it to failures of something not under their control - you’d like to donate your spare capacity to the community, but neither the current architecture nor the grand “someday” plans of high level peering really support doing that, while also meeting the needs that are funding your gateway deployments.
No, and that was not the argument. The argument was that TTN’s inability to share access to gateways prevents people from contributing to TTN while also deploying their own server to work around its infrastructure issues in order to be able to meet the needs that fund the installation of those gateways.
Maybe downtime is not the right word, but sometimes the backend does not receive packets over UDP for about 30 Minutes. And we see such “drops” on multiple connections at the same time. This does not happen very often, but once or twice per day. The rest of the time there are only some packets lost.
We have moved to a private account, and packet losses are nearly gone. But it would be better to have a reliable public network.
of course I fully agree… but it’s permanent ‘under construction’ … V3 is now on the horizon with new and more secure possibilities and very soon TTN has 10 k gateways around the world !
As long as suppliers like Kerlink do not support the new protocols things will not get better, i suppose? It would be very helpful to get more information, which gateways do support the current protocols.
There is a list of commectial gateways that should be updated. Some gateways like the Kerlink iFemtocell do only support the old Semtech SPF, which has a lot of quirks and flaws. When we started it looked, like there should not be any problem, but we found that the SPF currently looses up to 25% of the packets if the backend is busy. The new Gateway protocol is much more reliable.
The basic rule of thumb would be not to a buy a gateway where building the entire stack from source is not known to be a workable option.
Are you sure that isn’t possible with that particular Kerlink?
To some extent, even gateways somehow locked into to an old protocol may be able to be modernized by putting them behind a local translator, preferable inside any firewall/NAT (or co-located with it).
For example in LoRaServer’s (non-TTN) ecosystem, packet forwarders still typically speak the legacy protocol, but only as far as the “gateway bridge” translator, which ideally runs on the gateway itself. Due that, and you remove most of the common causes of data loss. Conversely if you run that gateway bridge in the cloud (perhaps co-located with the server) you suffer most of the issues with the old protocol, except perhaps the UDP server overloading TTN reportedly has issues with. Putting the bridge somewhere in between, ie between the gateway and the ISP may also be a path with the combination of being able to run it on a more easily serviced box, but still keeping the legacy protocol very local.