I’m trying to diagnose and troubleshoot a recurring scenario whereby a re-join is unsuccessful for a prolonged period.
I have a decentlab transmitter and to be fair RB has offered good technical guidance, but there is a lot more TTN moving parts here, so I’ll looking at the scenario from the network point of view.
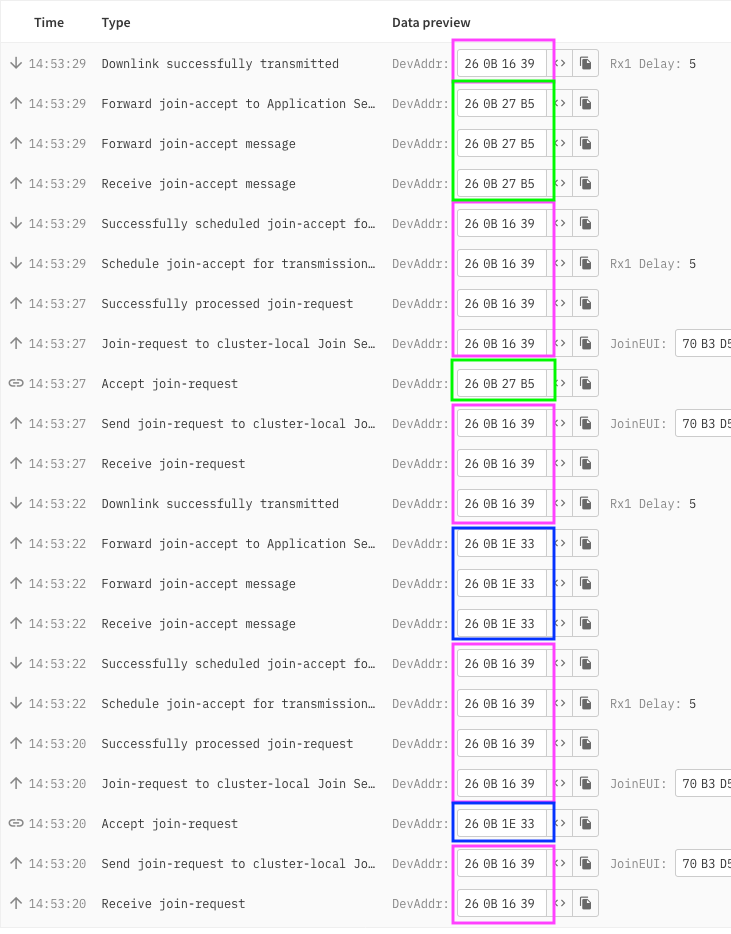
Symptoms - I see a rejoin where the device issues a JoinRequest 3 times, every ten minutes. The Join-Accept is issued by TTN but this - for some reason - does not work.
This transmitter is on a mountain 1080m above sea level, and each transmission is picked up by 25-35 gateways on TTN and brokered networks.
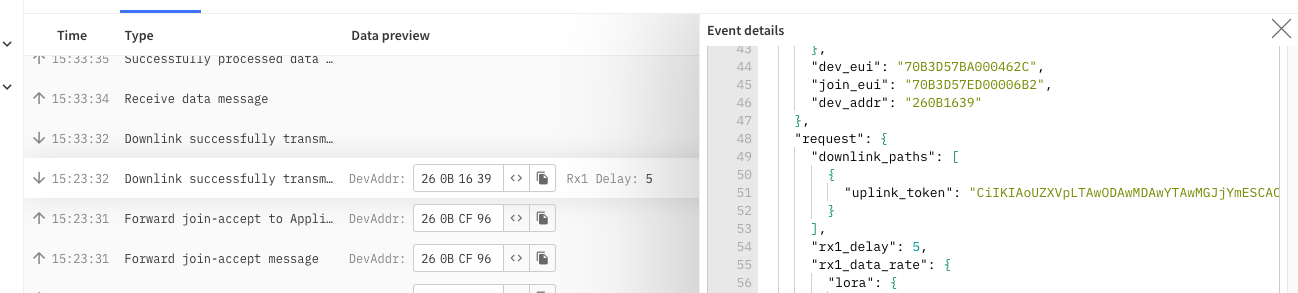
The “best” gateway is one of my own, (-95dB RSSI, +8dB SNR) but for some reason this doesn’t appear to the gateway selected by TTN to perform the downlink. (Aside: can we see the GW selected to handle any particular downlink? - I just can’t see a DL in the console for this GW, and I can’t see a GW in the JA logs)
It appears to me that the JA downlink is possibly just happening too late… looking at the device log, and inspecting the DevAddr as a marker for the current state of flow, it seems to be that a new JR has been issued before the last one has been delivered (by which time the device will have selected a new DevNonce rendering that old one invalid…). But, this might be a red-herring.
What puzzles me, is that at some point (maybe 10hours later) it will be accepted, and then what I might be able to do about this?
35-50 gateways gives us a lot (a very lot) of redundancy using TTN, but 10 hours without data every week means we’ll opt to use a different LNS if that is something that will resolve this, and resort to one GW.
Does any one have any other thoughts on what markers I can look for otherwise?
how configured esp what RX1 & RX2 values programmed in
how registered in TTN esp what ^. ^. ^ etc.
Re numbers rssi report likely just a value with -ve implicit
Re snr @ -15 might have expected a GW with better signal quality to be selected
A good SNR value will be SF dependent as LoRa has inherent capabilities….and limits.
What SF is being used for transmissions. Are you using e.g. default RX2 SF? (9?), may be marginal……for selected Gw etc.
Nick’s suggestion may be most logical and simplest route to solution/debug given the number of variables, moving parts, receiving Gws, in known Gw backhaul & forward connection latency, JiT queues etc….etc.
My guess is that it will be re-joining because a periodic link-check is failing to downlink.
That would fail with the same issue, (v.high-latency GW with rogue RSSI will be selected for downlink. )
There’s plenty of options if I want to run this through a single GW. We’ve got a reasonable number of LNS providers into the platform.
I figured having massive redundancy of gateways would be a good thing But of course playing the numbers game with community infra.
Luckily I know the operator of this GW and have filed a bug report in TTS. so there’s a coupld of routes for resolution.
It’s a DecentLab transmitter running factory config, and configured from the device repository.
So pretty vanilla. In fact the device is good, and has rejoined when planet earth offers some scenario that means the default selected gateway had just low enough latency to issue the downlink.
I’ve looked thorugh the TTS code and it only uses channel_rssi, currently rejecting only RSSI values == 0.0 and then just ranking on >= to provide the strongest signal, ignoring the actual link quality SNR.
And device type in hand is an exact match to what is listed in repository? Same firmware, same h/w build? Often there are variants and the devil is in the detail, also have you tried falling back to an earlier LW version - so if claimed 1.0.4 and registered as 1.0.4 have you tried 1.0.3, if it claims 1.0.3 have you tried using 1.0.2 etc…sometimes it works due to quirky MAC/device behaviours and assumptions…lots of moving parts in play!
Thanks @Jeff-UK ,
It’s not a device problem. it works fine in the lab.
Only when presented with the very odd scenario of rogue gateway issue positive RSSI values, that is also on a super-high latency link.
Here you go @descartes
It hasn’t been accepted yet.
In a list of 35 receiving gateways, all but one list negative RSSI values, just one (which ends up being the the selected downlik path) has a positive value. Looking at the source code, this is not invaldiated. I don’t even think the +ve 90 is likely a just inverted as it is 30km further away from the GW on my office which RX at 95dB. Stranger things have happened though
Actually, there is some adjustment by manipulating the RSSI and SNR into a single value with a simple heuristic.
// AdjustedRSSI returns the LoRa RSSI: the channel RSSI adjusted for SNR.
// Below -5 dB, the SNR is added to the channel RSSI.
// Between -5 dB and 10 dB, the SNR is scaled to 0 and added to the channel RSSI.
func AdjustedRSSI(channelRSSI, snr float32) float32 {
rssi := channelRSSI
if snr <= -5.0 {
rssi += snr
} else if snr < 10.0 {
rssi += snr/3.0 - 10.0/3.0
}
return rssi
}
But with a positive RSSI value, it’ll win in all cicumstances.
No idea.
I know the operator of the rogue GW so there’s hopefully something that can be addressed there - to work out why it reports +ve RSSI.
If neither of those work over the next few weeks, I’ll stick it on another LNS.
If my assesment is correct then with a malicious GW firmware one could game the network, get selected as the downlink path and drop downlinks on purpose, DOS-ing whatever nodes are trying to Join/link-check/Ack. You’d think it might get patched - if my working is correct?
Do you know the provenance of the GW and its history? Make/model/firmware/PF? COTS or homebrew? someone getting crafty and gaming Helium to get selected to handle data thereby getting increased rewards - but then moving it to TTN?! As you say a risk that (not at this extreme level) a smaller fudge could go largely undetected/not appear suspicious unless investigated in detail…
TTS source code available - have you eye-balled to see how exceptions might be handled/filtered out and rougue GW’s trapped?