when i send some payload from dragino lora shield(node) to the things network cloud using lg02(gateway) so i observed rssi values in the things network so my question is
Is that the rssi values showing in the things network is signal strength of the gateway which means the values received from the node. or there is any other method to find the rssi of the gateway!!
please help me because i want to test the range between gateway and node.
If monitoring on the gw console page of TTN, rssi will be the node received signal strength at the media converter.
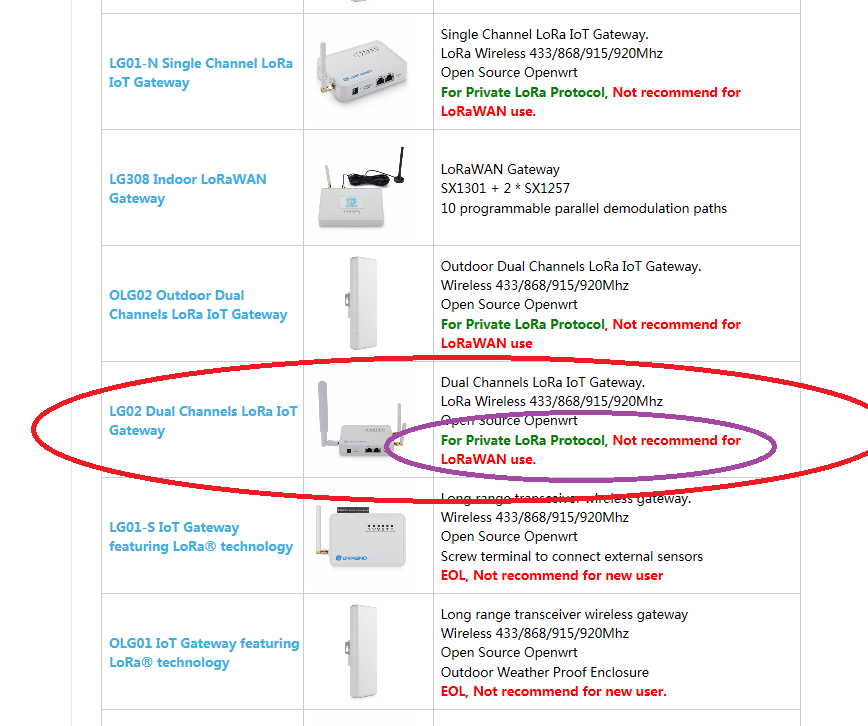
However, be aware that LG02 is not a LoRaWAN gateway, it is LoRa single/dual channel packet forwarder/LoRa media converter only and their use on the TTN network is disruptive to other users. Please disconnect it from TTN. They are deprecated and support is now out of scope for the forum.
how it disruptive to other users!!! and They are deprecated!! can u please elaborate because i am new to this because i planned to use this packet forwarder as a commercial purpose.
There have been several manufacturers of such faux gateways over the years and sadly it took a while for them to recognise the problems ensuing and even longer for their sales channels to catch up and update their own websites/info to highlight the fact they were LoRa only.
In the early days of TTN, when ‘proper’ GW’s cost >>$1000 these were a way of starting to use and experiment with LoRa and a subset of LoRaWAN, and were tolerated. Lots of web guides refer to them and give how toos on connecting to TTN and unfortuantely the Internet abhors censorship so its difficult to go around and weed them out. A simple search of the TTN Forum before purchase would, however, have flagged the problem and instruction to not use/connect to TTN.
A LoRaWAN gateway is capable of receiving on all 8 assigned channels/frequencies and multiple SF’s simultaneously, where these by definition can only handle 1 or 2 depending on config. That means they can give false impressions of local coverage to other users and in the case of devices using ADR totally disrupt the signal evaluation algorythms. In addition, and potentially worse still they present themselves as Gateways to the backend NS, which may, depending on signal strength, select your gw to send a downlink to a nearby node, this could be e.g a join request/acknowledge, ADR instructions as above or any of a number of MAC commands, or indeed a user payload downlink. Your ‘GW’ would be asked to send but would be physically incapble of completing the task. The user would not be serviced and the NS would have no way of nowing it hadnt worked!
Today compliant, 8 channel GW’s are really cheap - Dragino to a good one the LPS08, or some of ts larger brothers (LG308 etc.), and ofcourse there is the TTIG, plus low cost gateways from RAK, Pycom, iMST and many others ($70-$150) plus more capable units from RAK, Dragino, Multitech, Mikrotik, Teltelic, and again many others in the $150-350 range.
Nick fired off a series of quick responses whilst I was typing/compiling the more detailed one above (note this is not exhaustive! - if you study LoRa & LoRaWAN specifications, documentation and architecture you will learn there are potentially lots of other issues too). As noted they are disruptive and should not be used or if already connected should be exchanged for a compliant GW as possible - taking the faux gw offline in the interim.
This is true, and is the problem - these “fakeways” cause the ADR algorithm to tell nodes to switch to shorter range modes where they can no longer reach more distance true gateways. Even the very act of switching spreading factor means the node cannot reach the “fakeway” on the very same channel it previously did, because the non-gateway receivers used in these boxes are not just confined to a single frequency at a time, but also to a single spreading factor.
However this:
Your ‘GW’ would be asked to send but would be physically incapble of completing the task.
and this:
Are mistaken. Provided their software is careful to get the timing right (which it appears to be), fakeways have about the same downlink capability as actual gateways, and the same frequency agility as nodes… because they are nodes.
It seems there’s some confusion about the 8-channel/multi-sf concentrators: these monitor multiple uplink possibilities, but transmit with flexible settings commanded by the network at the time of transmission - they hop to whatever frequency and spreading factor is commanded for that packet. In many regions of the world, the frequencies used for downlinks are not even the same frequencies monitored for uplinks.
Some of these boxes may have slightly less downlink transmit power available, though by little enough that it’s not their issue compared to the lack of full uplink coverage. And some of what are promoted as actual multichannel gateways like in the ST micro kit have drastically less downlink power with a far weaker transmitter than most nodes.
Once you replace the illicit box that must not be used with TTN with an actual gateway, you’ll probably find that the range in both directions is moderately comparable.
Available transmit power may differ slightly, receiver performance may differ, local noise sources may differ, and in some regions downlink is performed at a different bandwidth than uplink.
But things like antennas have equal gain (or loss) both transmitting and receiving.
If you want to know the actual RSSI at the node, you’d need code to extract it from the node’s radio chip. There are versions of this floating around as part of LoRaWAN codebases, though historically some seem to have had an error in value determination. You’d then need to give your node a display, or to transmit the reading back up; if you chose to transmit it back up, keep in mind that those need to fit your fair usage uplink rate/duration allowance.
Ultimately RSSI is rather approximate; it’s often most meaningful in evaluating a change - if I put it here or there, if I use this antenna or that, or in a cruder sense which gateways a node is closest to, or which nodes are comparatively close/far from a gateway.
For such purposes the already available RSSI of node at gateway is what is usually used.
So are you advocating they should be used and are not disruptive? Or is this just your observation? I can tell you from bitter experience and direct £cost that they are!
Whilst technically agile for downlinks the reality is they are rarely set up that way. 5 out of 7 realworld deployments of these systems that I have inspected and had to troubleshoot then help mitigate against, and a great many instances reported by others, have experienced not only the 1st (uplink) problem, but downlink related problems too - with the owner/user finding major gaps in uplinks when they deployed their LoRa/LoRaWAN nodes (which should use any of the 8 available channels on a random basis). This is confirmed if you use forum search as over the years we often see users decrying the problem they are (effectively) missing ~7/8 messages (single channel PF’s) or ~3/4 messages (dual channel PF’s), when using these faux gateways. Recognising they cant talk on the same channels the next step is they then go on to fix the channels of their nodes to just using that one or the pair supported by the faux gateway - all traffic then goes over a more limited spectrum (disruptive congestion for uplinks), RX1 replies are then on the same channels (more - this time downlink - congestion). and as you note they then also take the next steps of locking the supported SF’s - usually to suite their own needs vs supporting the wider communities needs - again disruptive. In addition to stop the GW going deaf whilst handling wider community downlinks - on frequencies & SF’s their own nodes cant/wont use, they then also often selfishly take the next (logical in their eyes) steps of locking down the GW to only supporting the frequencies/sf’s their nodes use - further constraining their capabilitily and ability to service the local community. As I say disruptive to downlinks as well as uplinks.
When conducting area coverage surveys ahead of a ‘production’ deployment these devices can then intermittently present as ‘available’ suggesting coverage is present - leading to a false conclusion that an area has coverage and the efforts can move on to check elsewhere, only to find that once the coverage/trial deployment is complete and the client/user moves on to full production deployment they suddently find intermittent and/or completely abscent effective coverage, leading to a period of having to troubleshoot and debug deployments (at often significant cost) and then take corrective action - often meaning having to deploy an additional GW to cover up the inadequacies, or perhaps relocate several others to close the gap. Even then in high density node deployments having one of these ‘cuckoo’s in the nest’ can be VERY disruptive as node & hence NS will latch on to using one of these devices. In one instance the only solution we could find was to ‘surround’ the Cuckoo with real gw’s to ensure they were seen by the nodes rather than the disruptor. We we unable to exactly locate the Cuckoo beyond an approx 150-200 range and could not persuade the user to kill it or swap it out(*). In that case the local council that was affected had to buy 4 additional GWs to place approx N, S E & W of where the suspect device was to then mask from its nodes and ensure any reception or downlinks were then handled by the councils GW’s rather than being disrupted by the Cuckoo.
I would therefore assert that both my & Nick’s comments are indeed correct and representative of the real world. I agree with your observation about uplink and downlink activity often being on different channels in some parts of the world - I guess Australia is a classic example, but that does not change the general point.
As for your observation wrt Tx power for downlinks, again I agree but again does not change the basic general point and is just another wrinkle along the way. I would further note I have one of the ST eval kits and seeing the missing PA and diminished downlink Tx power (took a few days to realise what was going on and read up on the problem!) I would only ever use one of these in a test envrionment, perhaps with limited range constrained by geography/topography if not actually confined to use in the lab…and certainly will never deploy one of these in the field in a production system due to the fact that it could be disruptive for far nodes, or those trying to optimise behaviour under ADR, as you point out.
(*) I’m pleased to report that about 6mo-yr later I heard the cuckoo had gone offline and stayed off, we subsequently found out that the user in question was deploying additional nodes in the area and realised he was getting better coverage through the other community & council GW’s than with his own crippled device and simply switched it off - never to deploy a GW again!
No, I’m speaking about the facts - I agreed with you about the actual problem with walking ADR into a trap, and that because of that they must not be used on TTN.
It’s the erroneous claims about downlinks which I was correcting.
Uplink problems (“major gaps in uplinks”) are not downlink problems; it’s well established how non-concentrator based gateways have and (via ADR), cause uplink problems. The irony is that if their downlink didn’t work, they actually couldn’t cause such problems, but rather the opposite problem of the node side part of ADR fallback increasing SF to try to re-establish connectivity, or ultimately trying to do a new OTAA join.
The simple fact is that their limitation is in the uplink direction not the downlink one.
I would further note I have one of the ST eval kits and seeing the missing PA and diminished downlink Tx power (took a few days to realise what was going on and read up on the problem!) I would only ever use one of these in a test envrionment, perhaps with limited range constrained by geography/topography if not actually confined to use in the lab…and certainly will never deploy one of these in the field in a production system due to the fact that it could be disruptive for far nodes, or those trying to optimise behaviour under ADR, as you point out.
Even testing usage of such a thing with TTN is problematic; ironically, this device actually has the downlink problem which the single channel boxes do not have. In contrast, its uplink path works properly, while theirs do not.
Similar problem, but on the opposite path.
Separating the actual technical facts from misunderstandings is important.
I think it’s about high time we came up with one definitive document on the why’s & wherefore’s of the SCPF and it’s big brother DCPF and this thread seems to have got in to more of the detail than we usually do, so as @cslorabox and @Jeff-UK have different domain knowledge & experience, is there anything else to mention and I’ll create a summary.
The really loaded topic would be the technical fact that the proposed “ignore for ADR” checkbox to make mobile gateways safe would also make these non-destructive (doubly so if it were to activate automatically on any gateway that wasn’t reporting uplinks on a variety of channels/SF’s…)
In terms of policy, nodes intended to use them would still abuse one channel/SF (same as they would if used outside of TTN) but at least they’d no longer trap other people’s nodes.
In some regions with multiple uplink channel groups, it would be possible to entirely dodge the issue by agreeing to place the non-compliant devices and nodes on a different sub-band than the concentrator based gateways and nodes.
I fully understand if people don’t want to take those enabling steps; but in a technical sense using one or both is as safe as telling people to go make their own network is.
I’ve had the view that they are illegal and don’t meet the requirements of the radio spectrum regulations.
To use the ISM bands many of the regulations require the device to change channel on subsequent transmissions. This is to reduce the interference your transmission makes to other users. You change and the other systems nearby also randomly change, making one extra way of reducing the probability of one system blocking another.
So any single channel device, be it on Lora or LoraWan, is probably contravening the local spectrum rules.
Could you cite a reg which says that specifically, rather than the more common case where the allowed usage rate is contingent on the number of channels used?
Also in at least some places rules are different dependent on bandwith; using the wideband channel could make sense where that brings more permissive rules; normally that isn’t used much for uplink (vs being routinely used for downlink) as concentrator-based gateways can only handle one wideband fixed-SF uplink channel; but fakeways can only handle one frequency/SF/bandwidth combination at all…
Ultimately TTN policy is about if these things are allowed in TTN (presently they are NOT!) while only laws govern if they can be used externally to TTN.
Depending on where in the world there are typically 2 mitigation techniques to limit channel hogging, in EU we apply a duty cycle limit typically 0.1%, 1% or 10% depending on channel - we use the 10% DC channel for Downlinks so GW’s dont run out of capacity too easily. In other areas like US (I suspect for AU?) with US915 (AU915) there is a dwell time limit - a Tx can only stay on one channel for a max period - 400mS in US before having to frequency hop to another channel to start next Tx or continue. In some regions this might also be augmented/further constrained by requirements for LBT implementation in addition. That is one of the reasons why US (& I think AU) have more channels available (64) to allow for that hopping activity, where we simply limit based on DC. A typical GPS Sensor Payload might stay on air for ~1400-1800ms in EU at SF 12 but then can t TX again until DC time lapsed to allow next TX, where in US they cant use SF12 as that woudl break dwell time limit. As you say where the S/DCPF’s constrained on ferquency they quickly run out of capacity and artificially constrain ability to send Downlinks (disruptive to network operation as NS has no way to know it is sending through a crippled device and assumes the capabilities of a fully capable 8 channel GW) though as cslora pointed a correctly set up and programmed device could/should be agile enough to switch channels as needed once dwell time limit reached … in practice this rarely happens.
Believe this is all covered by the RED/EN regs in EU, FCC (part 15) in US, there are equivalents from ICC for Canada and others around the world - cant remember the AU regs/authority
Please stop conflating uplink and downlink capabilities, they have literally nothing to do with each other.
I said no such thing.
All gateways are agile enough to transmit on whatever channel is commanded; there’s no actual linkage in a gateway between uplink channel(s) monitored and downlink channels achievable if and only if commanded.
Since downlink capability is universal, it has literally nothing to do with which uplink channel(s) are supportable or used.
I appreciate the theoretical capabilities, as above I refer to realworld use cases and how I (and others) have actually seen these devices used and the impact they have. I appreciate your knowledge and observations, but I am clear of what is downlink related vs uplink, thank you
really?
Like I say it is the realworld use and configuration and how owners of such devices deploy and tweak them that causes many of the problems & behaviours we typically see…not some theoretical capabilities, hence the policy.
As noted your observations are appreciated, but further ‘discussion’ and exchange on this is unproductive and frankly futile. It is also way of topic. (RSSI values!)
On that side I welcome your comments to OP with respect to RSSI calculation & use and would broadly agree with you especially the
Which I suspect in part comes back to
and I guess various peoples interpretation of the core Semtech data sheets, (which IIRC have also evolved and adapted with tweeked algorythms over the years since the early pre-production drafts back in 2012 & 2013!)