Hello there, I’ve been having an issue since this morning that has been driving me crazy. I’ve looked everywhere, but I can’t find anyone with a similar issue to this one.
I have a class C multicast group set up in TTN, and I’m trying to queue a message to it. However, it always fails like so, constantly retrying to upload the message:

The “Schedule” message contains details about the error. Here’s the event:
{
"name": "ns.down.data.schedule.fail",
"time": "2025-03-18T09:08:25.057271779Z",
"identifiers": [
{
"device_ids": {
"device_id": "multicast-group",
"application_ids": {
"application_id": "gie-fuota-app"
},
"dev_eui": "70B3D57ED800405A",
"dev_addr": "DEADBEEF"
}
}
],
"data": {
"@type": "type.googleapis.com/ttn.lorawan.v3.ErrorDetails",
"namespace": "pkg/gatewayserver",
"name": "schedule",
"message_format": "schedule",
"correlation_id": "7ac4369a39844182a9743feb00524afe",
"code": 10,
"details": [
{
"@type": "type.googleapis.com/ttn.lorawan.v3.ScheduleDownlinkErrorDetails",
"path_errors": [
{
"namespace": "pkg/gatewayserver",
"name": "schedule_path",
"message_format": "schedule on path `{gateway_uid}`",
"attributes": {
"gateway_uid": "kona-enterprise-1@giefuota"
},
"correlation_id": "cc002b95bcc64c59917ac18f4b44d6aa",
"cause": {
"namespace": "pkg/gatewayserver/io",
"name": "tx_schedule",
"message_format": "schedule",
"correlation_id": "82dfb1470c284b4da29317d65c930f9a",
"code": 10,
"details": [
{
"@type": "type.googleapis.com/ttn.lorawan.v3.ScheduleDownlinkErrorDetails",
"path_errors": [
{
"namespace": "pkg/gatewayserver/io",
"name": "rx_empty",
"message_format": "settings empty",
"correlation_id": "39374b03b9954850bab3a1c440d925b9",
"code": 9
},
{
"namespace": "pkg/gatewayserver/io",
"name": "rx_window_schedule",
"message_format": "schedule in Rx window `{window}` failed",
"attributes": {
"window": 2
},
"correlation_id": "571165e0e9ea4345bdf8d80aec2457a2",
"cause": {
"namespace": "pkg/gatewayserver/scheduling",
"name": "no_clock_sync",
"message_format": "no clock sync",
"correlation_id": "eb4a23436c3c4c1f84b78351e1a61764",
"code": 14
},
"code": 14
}
]
}
]
},
"code": 10,
"details": [
{
"@type": "type.googleapis.com/ttn.lorawan.v3.ScheduleDownlinkErrorDetails",
"path_errors": [
{
"namespace": "pkg/gatewayserver/io",
"name": "rx_empty",
"message_format": "settings empty",
"correlation_id": "39374b03b9954850bab3a1c440d925b9",
"code": 9
},
{
"namespace": "pkg/gatewayserver/io",
"name": "rx_window_schedule",
"message_format": "schedule in Rx window `{window}` failed",
"attributes": {
"window": 2
},
"correlation_id": "571165e0e9ea4345bdf8d80aec2457a2",
"cause": {
"namespace": "pkg/gatewayserver/scheduling",
"name": "no_clock_sync",
"message_format": "no clock sync",
"correlation_id": "eb4a23436c3c4c1f84b78351e1a61764",
"code": 14
},
"code": 14
}
]
}
]
}
]
}
]
},
"correlation_ids": [
"as:downlink:01JPM85RMBJRXDPR9Z91T2X3KC",
"ns:transmission:01JPM85RV0NVKRMWND9RVAT9YK"
],
"origin": "ip-10-23-4-101.eu-west-1.compute.internal",
"context": {
"tenant-id": "CghnaWVmdW90YQ=="
},
"visibility": {
"rights": [
"RIGHT_APPLICATION_TRAFFIC_READ"
]
},
"unique_id": "01JPM85RV14W94CJ3WBHTGHYKA"
}
The only thing I was able to find about this issue was this code which I’m guessing is the source for the TTN message server. If so, then I understand the following:
- The
rx_emptyerror makes sense because it cannot use the rx1 window as it is class C only, so it is probably misconfigured and has its frequency set to 0 - The
rx_window_scheduleerror, now, I have no clue. The cause is a “no_clock_sync” exception, but looking at the code it’s not clear to me what this clock means, why it needs to be synchronized, or how to synchronize it.
Here’s more background info in case it is useful:
- I’m using a single gateway, a Tektelic Kona Enterprise, with Basic Station installed. I updated it around last month.
- The multicast group is configured as follows:
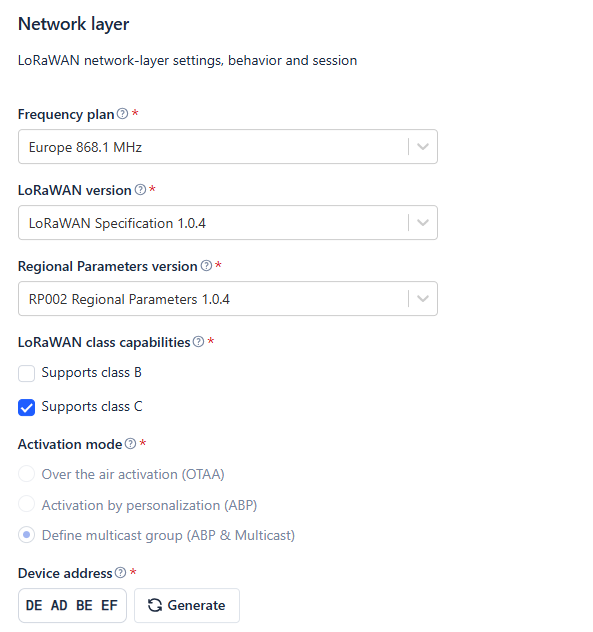
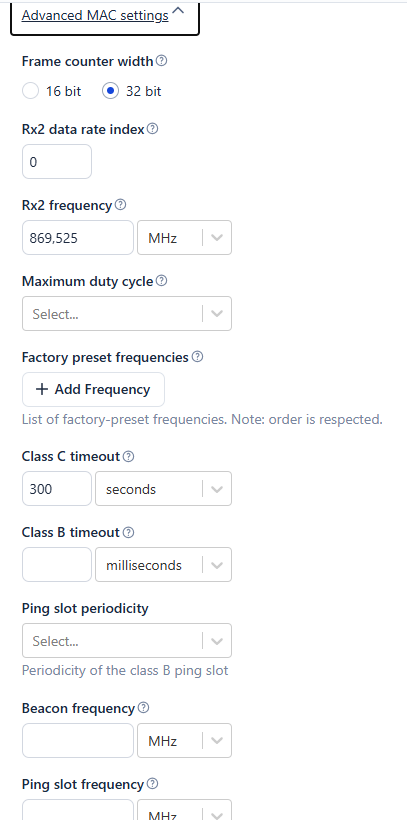
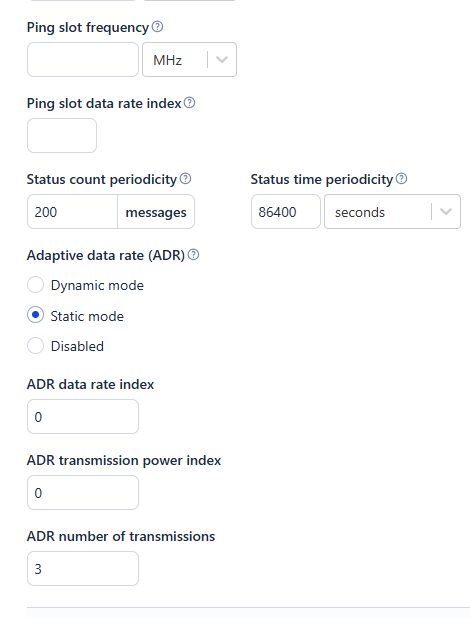
I’m new to the world of LoRa and radio communication in general so any information merely tangential to the issue would be greatly appreciated. And if you’ve read thus far - thank you for your time ![]()
Alejandro