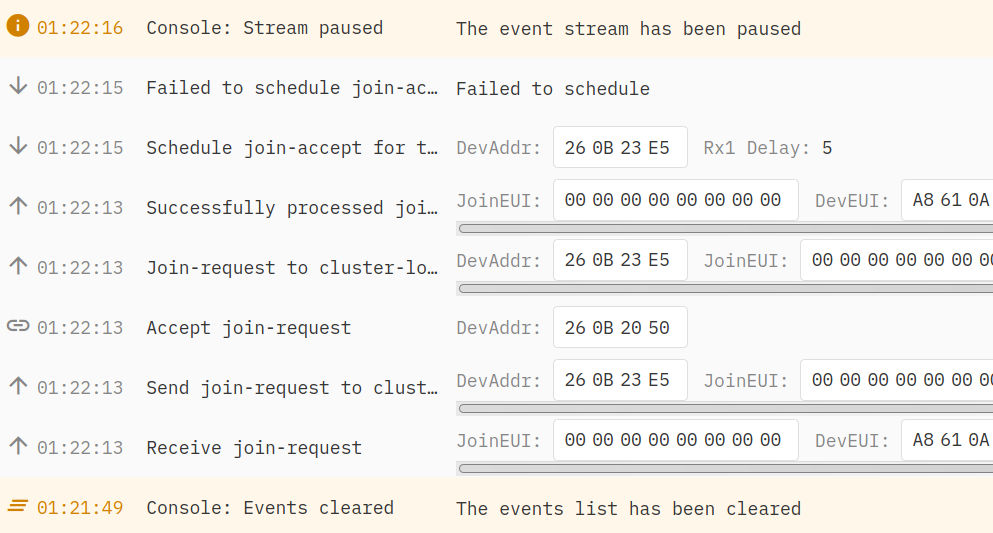
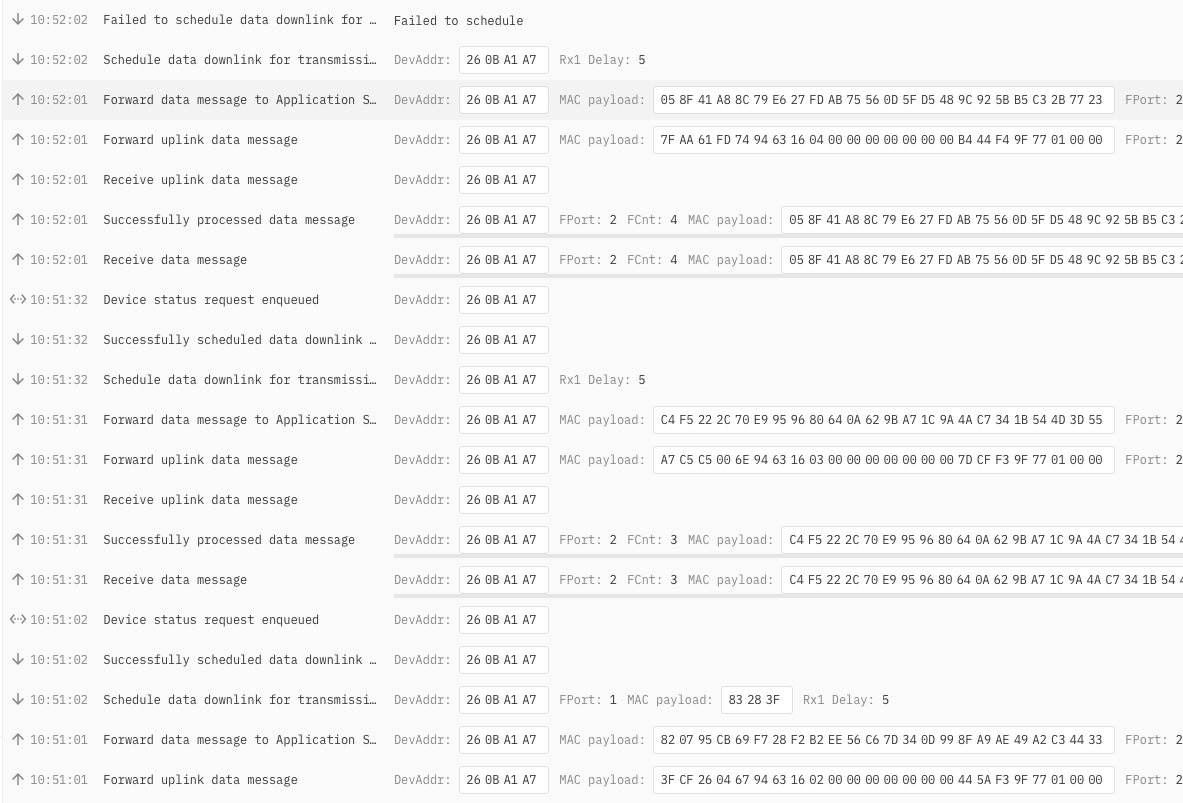
Today I tried to see what was the problem with “failed to schedule join-accept join” error.
So I looked in the json data that can be seen in live data.
{
“name”: “ns.down.join.schedule.fail”,
“time”: “2021-01-29T14:25:27.190686201Z”,
“identifiers”: [
{
“device_ids”: {
“device_id”: “mkr-wan-001”,
“application_ids”: {
“application_id”: “mkr-wan-13xx”
},
“dev_eui”: “A8610A3039426705”,
“join_eui”: “0000000000000000”,
“dev_addr”: “260B23E5”
}
}
],
“data”: {
“@type”: “type.googleapis.com/ttn.lorawan.v3.ErrorDetails”,
“namespace”: “pkg/gatewayserver”,
“name”: “schedule”,
“message_format”: “failed to schedule”,
“correlation_id”: “11a43244112e4505a3ea3f092041f15f”,
“code”: 10,
“details”: [
{
“@type”: “type.googleapis.com/ttn.lorawan.v3.ScheduleDownlinkErrorDetails”,
“path_errors”: [
{
“namespace”: “pkg/gatewayserver”,
“name”: “not_connected”,
“message_format”: “gateway {gateway_uid} not connected”,
“attributes”: {
“gateway_uid”: “blu-gtw-001@ttn”
},
“code”: 5
}
]
}
]
},
“correlation_ids”: [
“gs:conn:01EX7875FMWC41TCKD2A6Q4SRT”,
“gs:up:host:01EX7875FX7KMXQFRA47V5FHFX”,
“gs:uplink:01EX78HMAEGBSPENJN2240PR4F”,
“ns:downlink:01EX78HP4N9VPEC6ME1TWRH3A8”,
“ns:uplink:01EX78HMAFJ1KFKHP8QSJKDNX2”,
“rpc:/ttn.lorawan.v3.GsNs/HandleUplink:01EX78HMAFQ1VY0VFT49NDSAA1”
],
“origin”: “ip-10-100-14-196.eu-west-1.compute.internal”,
“context”: {
“tenant-id”: “CgN0dG4=”
},
“visibility”: {
“rights”: [
“RIGHT_APPLICATION_TRAFFIC_READ”
]
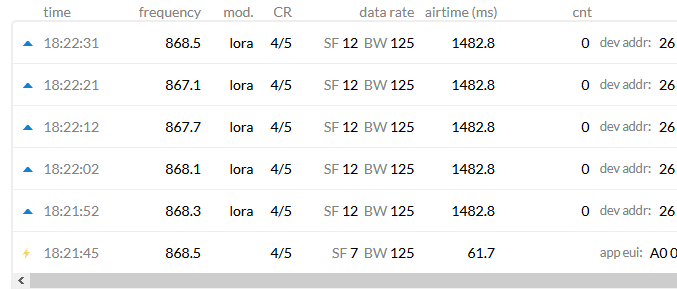
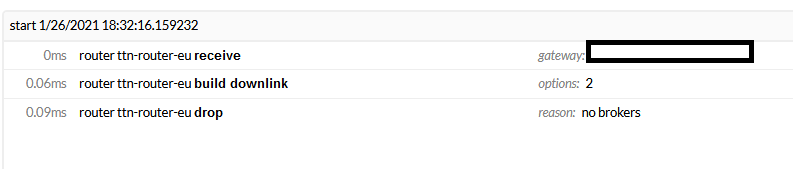
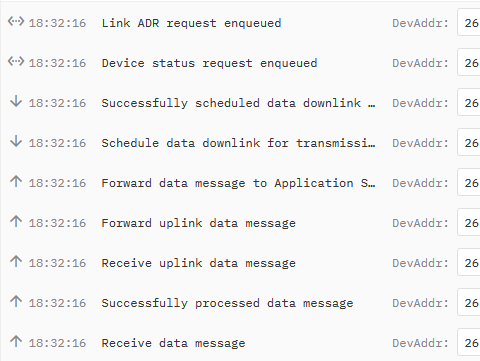
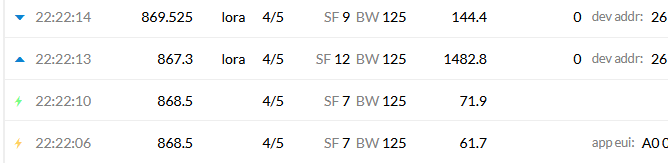
So the problem was that the gateway had a “not connected” status, even if was connected.
To remember that my first problem started because I tried a downlink message from console. That not worked, so making some tries including power cycle device to force a rejoin (without success), but also switching back from Basic Station to UDP forwarder.
It looks like that one switches from Basics Station CUPS to UDP forwarder there is something in v3 database that lets status to “not connected” in gateways management (but in console the gateway is marked as connected).
When I switched back Laird Rg186 to Basic Stations than the end device join had success.
hat said I have always the problem with dowlinks, with always error for being “not connected”.
{
“name”: “ns.down.data.schedule.fail”,
“time”: “2021-01-29T15:02:08.307504705Z”,
“identifiers”: [
{
“device_ids”: {
“device_id”: “mkr-wan-001”,
“application_ids”: {
“application_id”: “mkr-wan-13xx”
},
“dev_eui”: “A8610A3039426705”,
“join_eui”: “0000000000000000”,
“dev_addr”: “260B725C”
}
}
],
“data”: {
“@type”: “type.googleapis.com/ttn.lorawan.v3.ErrorDetails”,
“namespace”: “pkg/gatewayserver”,
“name”: “schedule”,
“message_format”: “failed to schedule”,
“correlation_id”: “4e044e4ca07d488d8e41e52daaef695f”,
“code”: 10,
“details”: [
{
“@type”: “type.googleapis.com/ttn.lorawan.v3.ScheduleDownlinkErrorDetails”,
“path_errors”: [
{
“namespace”: “pkg/gatewayserver”,
“name”: “not_connected”,
“message_format”: “gateway {gateway_uid} not connected”,
“attributes”: {
“gateway_uid”: “blu-gtw-001@ttn”
},
“code”: 5
}
]
}
]
},
“correlation_ids”: [
“as:downlink:01EX79HVQ3M5CXQEQW0D7C65M3”,
“gs:conn:01EX79JY7G7MY03J4WN3K0BCFV”,
“gs:up:host:01EX79JY7V5FHWG8WKVJGNXYCX”,
“gs:uplink:01EX7AMV8EN02YGYTMR1NB1KSC”,
“ns:downlink:01EX7AMVNJ1JAD2YQVFGJ98FNJ”,
“ns:uplink:01EX7AMV8HJZ7D2JRWBDNEN2G9”,
“rpc:/ttn.lorawan.v3.AppAs/DownlinkQueueReplace:a8c1c3c7-349f-4d11-a97f-161faebfc197”,
“rpc:/ttn.lorawan.v3.GsNs/HandleUplink:01EX7AMV8GKVNXCVD5B99FTC5G”
],
“origin”: “ip-10-100-14-196.eu-west-1.compute.internal”,
“context”: {
“tenant-id”: “CgN0dG4=”
},
“visibility”: {
“rights”: [