Good to know. Perhaps @wolfp could verify how long he’s leaving the gateway on and perhaps someone, @htdvisser ?, could verify how quickly over a few hours the rate limiting should cut in?
How can a database lookup of a device via it’s DevAddr when we know the gateway EUI to narrow it down take ‘at least a few hours’?
We aren’t asking you to police every situation, we get lots of misbehaving nodes talked about, this time it’s about one that is way off the scale.
I’d ask @wolfp to remove the edit to post 13 and add it as a new item as it makes a nonsense of the replies that follow.
Hi Johan, whilst I can appreciate the distate for doing this the problem here appears to be that a nodes behaviour is causing a GW to (potentially) breach radio regs. TTI doesnt own and run the GW, the users do - and it is the user that is on the hook legally for any breach…and we have to trust that the Things NS is doing the right thing and stopping Tx where there is a risk of exceeding legal duty cycle. - Any discussion of TTN FUP in this instance is a red herring as TTN can waive this as it wishes, however breaching regs is not an option.
Can we confirm if regs indeed being breached? If so we need TTI team to step in and assist…
Hylke stated
Its good to get that explaination of the change of window as make all clearer and as stated allows for bursty activity. But question is are we 100% sure stack if running ok, no bugs and no breach (in this case) as stated there has to be 100% trust from the community users that the stack is doing its job if we are not to be on the receiving end of (potentially substantial) fines or worse
@wolfp Wolfgang, can you monitor closely and capture >>1hrs dta for this one node and check wrt the 1hr duty cycle limit and report back please.
There is of course the other point that is being missed here in that it is not just a legal problem but also when a GW is Tx’ing it is not listening and thereby denying coverage to the local community whilst servicing this one rogue node - that is back int FUP territory - and is another good reason for nailing it where we can!
Given that things like the UDP protocol are effectively stateless, that seems a bit odd.
Are you profiling the rolling microsecond counter against clock time, and declare a new connection when you see a “jump” not explained by rollover or varying network latency? And what would be the benefit of doing so?
It would seem that such an algorithm, or connection state of an actually connected protocol would be very prone to false-resets, for example I have a non-TTN system where an packet forwarder state actually does matter, and I can see the LTE backhaul go up and down many times while the packet forwarder itself keeps running - that the low level transport (in say, an MQTT rather than UDP based backhaul) reconnects really doesn’t mean anything when the packet forwarder process continues.
I’ve never seen a duty cycle regulation that contained an exception for “restarts” anyway. For debug/testing purposes an explicit “reset duty cycle” button in the console would probably make more sense.
Today this node (Dev Addr: 260B3023) made 25 unconfirmed downloads with 12 bytes and 42 confirmed uploads with 27 bytes between 15:16 UTC and 16:16 UTC with SF12/125.
At 16:15 UTC it switched to SF9/125.
At 16:45 UTC it switched to SF10/125.
My gateway is up since one day without reboot.
Yesterday it made 40 uploads (27 bytes) and 40 downloads (12 bytes) between 08:30 UTC and 09:30 UTC with SF12/125. But this was short (1h) after I booted my gateway.
In the late afternoon the node changed from SF12 to SF8 but today in the afternoon it was back to SF12 again.
Today this node (Dev Addr: 260B3023) made 30 unconfirmed downloads with 12 bytes and 41 confirmed uploads with 27 bytes between 09:00 UTC and 10:00 UTC with SF12/125.
imho this one node consumes all of (more than ??) the legal airtime of my gateway. There is no time for anyone else left.
you dont say which band the gw is txing…rx1 ie. 1% band/subbands, or rx2 10% band. are all the rx1 downlinks on same freq or distributed (as that will also affect dc calculations)… need a lot more detail before we can judge.
We have identified the offending device and are trying to force it to a lower duty cycle. Hopefully this device is compliant with the LoRaWAN specification and respects that instruction, otherwise there’s unfortunately nothing we can do.
To be clear: this is a one-time intervention by staff, we’re not going to do this manually for every device that disrespects the fair access policy. As @johan already commented, we’ll add automatic detection of such devices, and handle them accordingly.
We value your privacy and security, so TTI staff doesn’t have easy access to the database.
The community is welcome to review the source code of The Things Stack to ensure that it’s implemented correctly. The source code for duty cycle enforcement can be found here.
In the case of the Packet Forwarder protocol that isn’t actually the case. Whenever the gateway restarts, it starts sending packets from a different port number, and our systems detect it as a different connection. Furthermore, when this happens, there’s a good chance that a gateway reconnects to a different physical server (we run multiple instances of the Gateway Server), which wouldn’t have the state of the previous connection.
A change of source port isn’t unique to a packet forwarder restart. With many gateways behind NAT there’d be a new source port any time a blip in connectivity created a new NAT mapping, especially but not uniquely with an LTE modem. This can happen pretty frequently in some installations.
Apparent IP address could change, too - all while the packet forwarder keeps running, unless the gap exceeds its give up timeout (but restarting the forwarder hardly helps)
That may make for some interesting edge cases given threads of the same packet forwarder use distinct sockets with distinct source ports.
Anyway, it seems likes an issue in the distribution design that makes the information to do regulation-compliant duty cycle not available on a gateway id basis the way it needs to be. With the source port of some likely to change more frequently than imagined, “session” based enforcement won’t reliably meet the regs.
I don’t have systems in the regions where it applies, but I do think this needs further architectural thought.
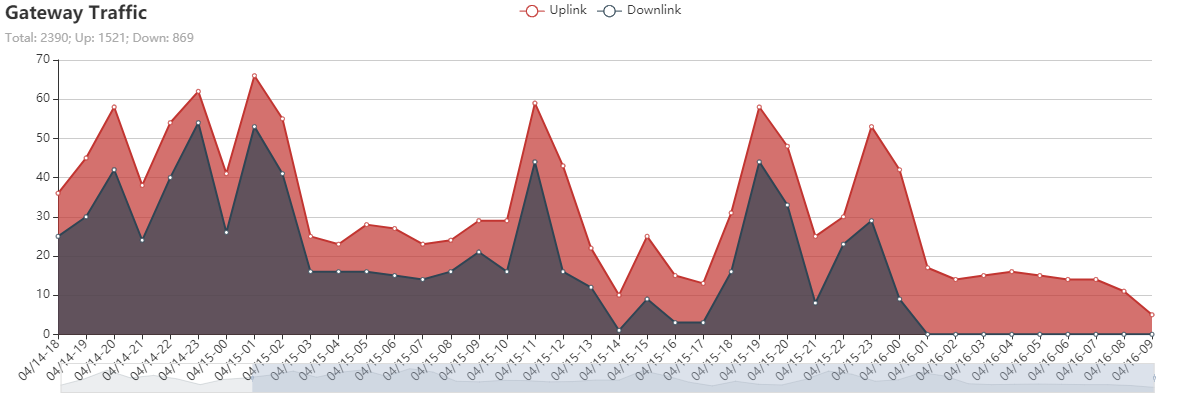
still looks like a very high downlink to uplink ratio and tracks well suggesting someone or many nodes locally using confirmed messages?! May be worth digging deeper and perhaps using local TTN Community to track down and ‘educate’ such users
it was our device and I just saw the changed device description which mentioned this thread. I apologize for the problems it caused and I just deleted it in V3 because I don’t have physical access to it right now to turn it off. I haven’t checked TTN for the last three weeks because I was sick. Maybe there should be an automated email notification for FUP violation or other device related problems?
About this problem: The device is an Adeunis Delta P which is sitting in a lab for testing purposes. It’s configured to transmit confirmed packets every minute (Adeunis is following the LoRa specifications afaik).
Confirmed packets every minute normally isn’t a problem, because we are usually providing our own gateways with the sensors to have a very very short airtime and support the TTN community by adding more and more gateways throughout Germany. If we know the distance and therefore the airtime is bigger, we are adjusting the frequency plan and rate of sending data accordingly.
But in this case Mouser sent us a gateways with the wrong frequency so we now had to wait to get the correct one to the lab. We haven’t seen any data coming in when the sensor arrived, so we thought there probably is no gateway nearby and it shouldn’t be a problem to let the sensor be activated.
Only when the gateway has arrived in the next couple of days on site and is working properly, I will add the sensor again to V3 so it won’t cause any more trouble because of the long distance from the lab to your gateway, @wolfp
Even away from TTN Confirmed packets should be used only sparingly as when Txing the confirmation the GW is deaf to ALL uplinks form ALL other nodes - just because a spec says it CAN be done does not mean it SHOULD be done. In the context of TTN there is a FUP limit of 10 downlinks per day - that includes join process, MAC commands, confirmed message acks etc. Even if close to GW, reducing on air time the limit still applies and sending/requesting every minute is 140x FUP limit!
Is it just one sensor per GW or are there multiple sensors per GW you deploy? If so the cumulative effect is that you might be effectively launching a DoS attack against your own infrastructure and risk - in the case of high sensor counts or high local density - triggering a cascade collapse of your deployments - and if your own GW’s run out of airtime capacity the TTN NS will start scheduling the downliks though the next nearest (from signal strength POV) GW in the community thereby propogating your DoS to other parts of the community! If your nodes dont see the confirmations they assume it didnt get through…and try again…and if that doesnt get through they try again…and again…and again and so it snowballs!. Please rethink how you deploy as far from adding to GW coverage for the community you may be inadvertently be causing intermittent black outs of local coverage…if you must do this consider a private deployment vs CE, and also consider carefully the use of spectrum for this scarce public resource (even if you go private if you see cascading that you can live with the increase in airtime that results will impact all local spectrum users). /rant-off!
thank you for removing your node from TTN.
This diagram shows what happend after you removed it yesterday in the late evening:
I agree with you that the owner of a node should be informed if there is something wrong with his node. Maybe with colors in the console:
Green: Compliant with FUP and with the law
Yellow: Not compliant with FUP but compliant with the law
Red: Neither compliant with FUP nor with the law
An email notification could also make sense but this all is up to the TTN-team because imho this is not easy to do.
Nevertheless in EU the owner and the user of a node or a gateway is responsible for what the device does.
btw: there is also a thread in the German IOT-Forum concerning this topic: Probleme durch Node mit rücksichtslosem Verhalten - TTN Köln - Forum IoT-Usergroup.de (iot-usergroup.de)
Yes we are. And this has already been brought to their attention 3 years ago. Their first firmware release didn’t allow unconfirmed uplinks at all, as a result of our (TTN and community members) requests they at least made it possible to switch to unconfirmed packets. Still not ideal, but there is no way to force them to clean up their act apart from not buying their sensors.
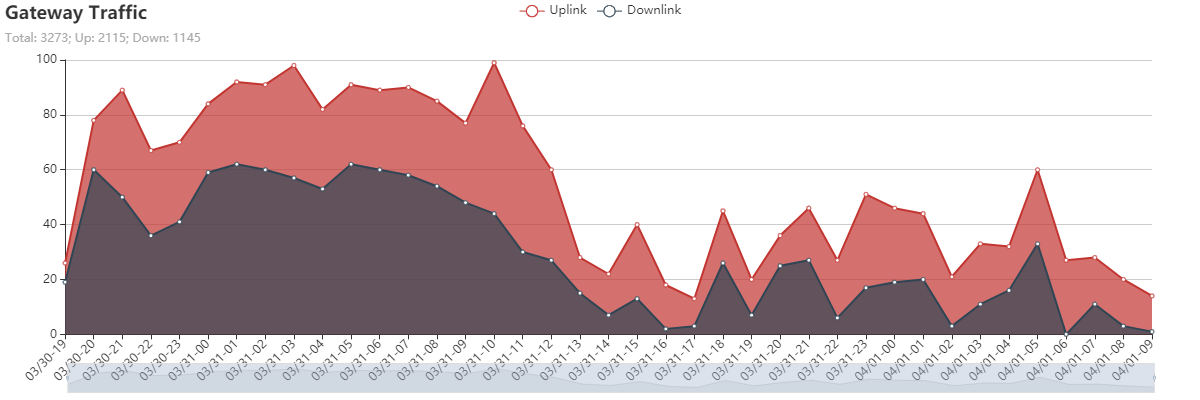
 still looks like a very high downlink to uplink ratio and tracks well suggesting someone or many nodes locally using confirmed messages?! May be worth digging deeper and perhaps using local TTN Community to track down and ‘educate’ such users
still looks like a very high downlink to uplink ratio and tracks well suggesting someone or many nodes locally using confirmed messages?! May be worth digging deeper and perhaps using local TTN Community to track down and ‘educate’ such users