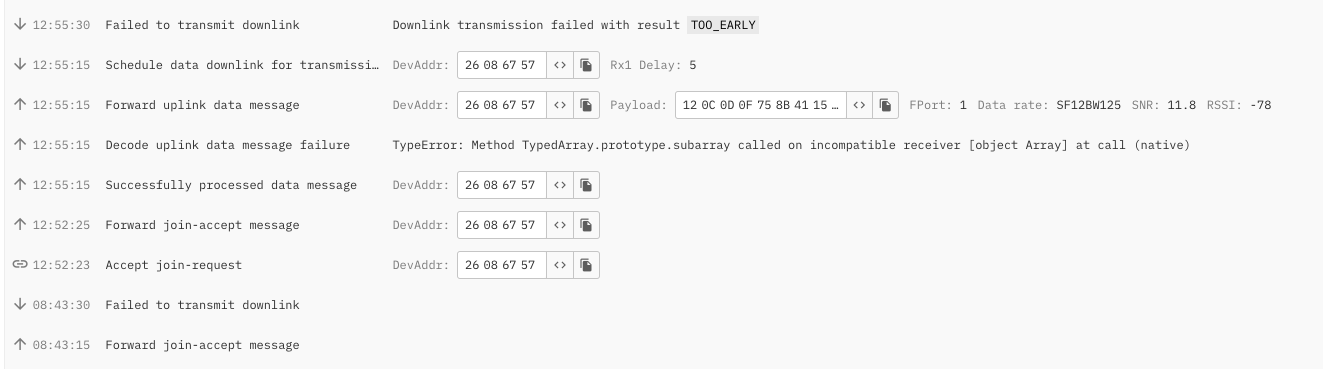
and in the Gateway Log in the TTN console I see an “Downlink transmission failed with result TOO_EARLY” error.
All I see now is simply Gateway stats in the log. On the device something similar to the following keeps repeating:
WARNING: [up] ignored out-of sync ACK packet
INFO: host/radio[0] time offset=(1664373131s:846742µs) - drift=-195µs
INFO: [down] received out-of-sync ACK
INFO: [down] received out-of-sync ACK
INFO: [down] PULL_ACK received in 2894 ms
INFO: [down] PULL_ACK received in 133 ms
INFO: host/radio[0] time offset=(1664373131s:846548µs) - drift=-194µs
INFO: host/radio[0] time offset=(1664373131s:846355µs) - drift=-193µs
I have tried increase the “Schedule any time delay” in the TTN console from 530ms to 2000ms (and then later to 5000ms), but this hasn’t changed anything.
Everything ran fine when the end devices was tested prior to shipping the end devices and gateway to the place of installation, but when deployed at the location where the cellular network seem to be slightly worse the issue appeared and none of the end devices are sending packets.
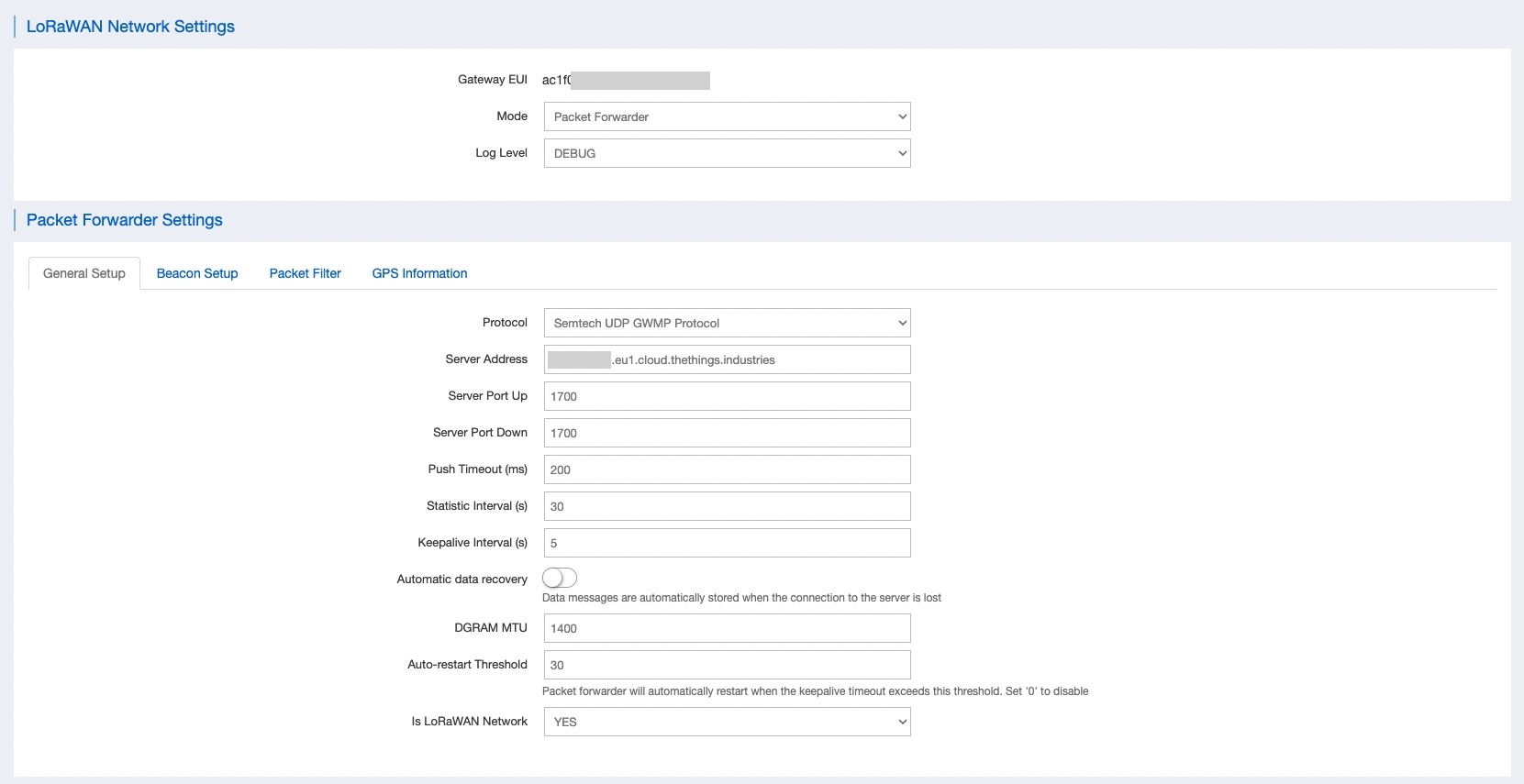
The following LoRaWAN settings are used on the Gateway
The first thing to consider is that though you arent seeing packets anyhow if anything this would make matters worse. Assuming the current TTN (V3) default of RX1 5sec (5000ms) after TX1 then you are saying dont even schedule until those 5s have passed - and then you get backend/network delay on top so device would miss the message even if eventually sent…even 2000ms is high and for devices where there are perhaps legacy deployments with RX1 set at 1 or 2 sec or where user overrides console default for newer devices to set a shorter time you again risk/guarantee a miss. Can you log into the local console for the GW at deployed site and carry out some ping checks & round trips to see what common sites are showing for the network delay as compared to those your saw on the bench when commissioning (you did test and capture, right?) to inform your decisions when making changes. Also given TTN sits behind load balancers and doesnt respond directly to targeted pings you might try some of the cloud infrastructure/cluster ping/transit time tests that have previously been called out on the Forum by other users concerned about round trip/response times (Forum search top right). Which PF are you running on the 7268, how configured?
UPDATE: Ignore last two questions - just expanded your picture and see you are running SMTC PF…and on a private instance of TT Stack vs running on the TTN (AKA TTS(CE) ) deployment… that changes scope and question response markedly as assume you will not have legacy nodes etc…
That only impacts Class C devices - are you using Class C?
All the devices have stopped working? Or do you mean the gateway is not hearing the uplinks or, more likely, the gateway is unable to relay the uplinks to the TTI instance?
As you appear to be able to login to the gateway, can you tell which of the three it may be?
Are gateway alive messages appearing on the console?
No, I’m using Class A. So this doesn’t impact anything at all regarding Class C?
The latter. The devices should be working fine and I see attempted uplinks in the Gateway log from the packet forwarder (Semtech UDP packet forwarder), but the gateway is not successfully sending them to the TTI instance.
Gateway status messages are appearing in the console
If there has been no change to GW configuration or setting in TT console then conclusion would be a backhaul problem…did you test on cellular on the bench or via direct network connection locally? If only used WiFi/Enet to test you may want to pull GW back and check locally on cellular…If tested on cellular have you confirmed devices functional in the field - e.g. no ant issues/battery problems etc - use SDR to catch/confirm transmissions if needed - with messages arriving ok in local gw console? Have you confirmed good GW function with a known good canary/commissioning device say 20-200m away from GW? Is the cellular provider on site different to that in the config/bench location? Some network providers block/limit Port 1700… but then I would expect status messages to be blocked
It was tested using cellular as well before deployed on site and it worked fine, however the cellular network had better signal when tested than it has now on site.
We have already deployed similar setups like this many different places with varying cellular connection and distance between end devices and gateway. This is the first time we have had this type of issue.
The network is different in the sense that it is a different network provider in a different country. So yes the backhaul could be the problem, but I was hoping we could solve it somehow without e.g. connecting the gateway through ethernet. We have tested it on many different networks and again this has not been an issue until now.
The field nodes are placed around a building, and the gateway is placed somewhat in the middle of the building. Estimated distance between 5 and 50 meters. Some through a few thing wooden walls. We have had fine signal strength in much more difficult environments.
Different enough that iNet round trip/transit times could be an issue or perhaps driving a change of TT Cluster location?.. especially if cellular signal marginal?
Potentially yes in that basic SMTC PF is UDP based with no QoS/certainty of delivery - packets are just thrown out on a wing & a prayer and whilst most will get there…!, where BasicStation is more secure and being TCP/IP based will have opportunity for replay/redelivery/easier network snooping/diagnostics etc. Also have you confirmed that the ‘foreign’ service provider is routing/transiting UDP packets through ok? (again arrival of the staus messages would suggest yes…)
Use the below to test, what cluster are you working to?
You can configure your gateway to any one of the 3, it is frequency independent of you end devices (So to the au1 you can have a gateway that is EU frequency band)
There are no such things as attempted uplinks. Either an uplink arrives at the gateway or it doesn’t. If it does and the CRC is correct it will be forwarded to the back-end. As the status messages arrive, the uplinks should arrive as well.
The RSSI shouldn’t be a problem. The sensors are placed close by.
Thanks, we will try this out then!
I assume they are, yes. It is possible for us to ssh into the gateway and configure it as needed.
Yes.
We are using the eu1 cluster, and the gateway + end nodes are placed in Europe.
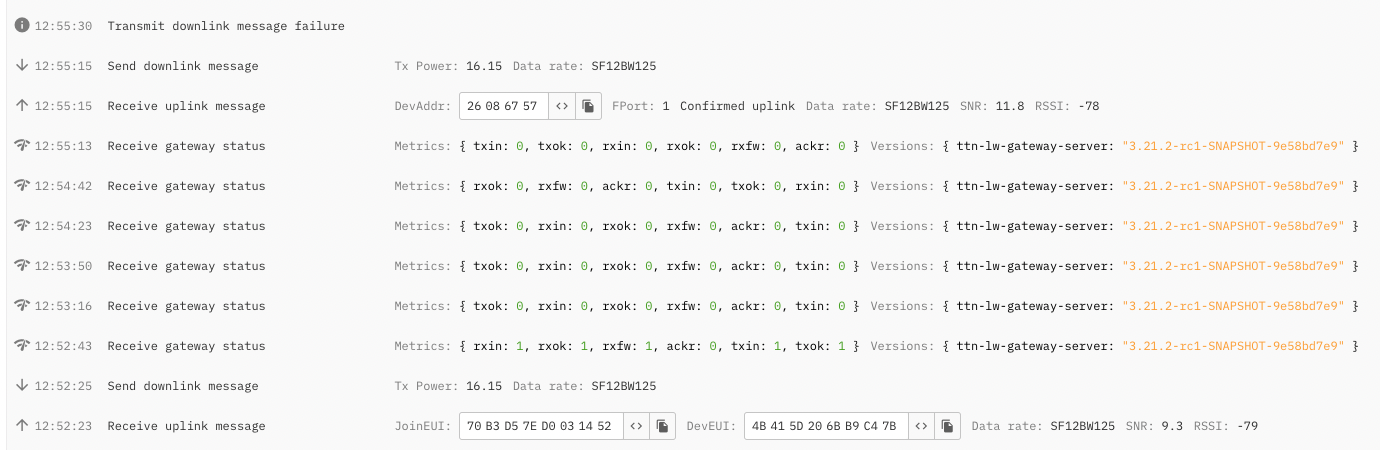
Sorry for the confusion. We see some some sporadic CRC errors in the log, but some seem OK. This is what the console looks like for the gateway and for one of the devices: