Dev nonce re-use is technically illegal. You’re as responsible for storing that, as you are for storing the frame count in an ABP session - OTA doesn’t erase the problem of needing to store stuff, it just moves it.
Illicitt re-use tends to happen with LoRaWAN stacks that aren’t connected to an actual random number generator and instead start at a predictable dev nonce, then count linearly forward from there.
Hopefully it will eventually hit an unused value, but the reality is that this is buggy node software that violates the LoRaWAN spec.
So I had to shut down the sensor for an hour or so and then restart it. This cleared the problem but its not ideal as I do not need to be waiting around an hour every time a battery needs changing. Apart from the obvious idea of having the unit run on an alternate power source while the battery is being swapped out, does anyone have any ideas how to make this less painful?
We’d need to know what LoRaWAN library you are using - it shouldn’t occur with OTAA on MCCI LMIC 4.1 using LW v1.0.3 on the console. Or at least it doesn’t for me and my recent testing has provoked several joins without issue.
In the design of LoRaWAN, nodes are required to maintain state through that. They’re just not supposed to be cold restarted.
People think that OTAA eliminates this need, but in reality it only moves it - instead of remembering the session details, now you have to remember the used dev nonces.
As a hack on the requirement, stacks will try starting with a random dev nonce, and then counting linearly forward from there with each attempt. This classically fails if a given port to hardware doesn’t have an actual random number generator implementation, since it will always start at the same “random” number like 0 (hey, as Randal Monroe points out, a constant could have been chosen by a fair dice roll!) and then count forward - meaning each join takes at least one more attempt than the last one.
Complying with the spec is better than banging ones head against the wall until non-compliance finally reaches a working nonce…
And sleeping a TTGO ESP32 board is an art that most people end up actually effectively turning off the device as it only preserves very selected parts of RAM so you have to consciously aka explicitly save and then recall between ‘sleeps’.
Hi, I seem to be getting the same issue, I have a Meter supplied by others with a mains power supply, and I’m using it for testing. When it is rebooted I get the same error as you guys have, reading the posts I see why the problem occurs. As this unit will one day be out in the field for real it is likely to be rebooted at least a couple of times on a remote site.
So how to “fix” or at least work around it, is it best to delete and add again as a meter, or just wait for it to cycle through its “random” numbers until it gets to one it’s never used before.
Hi All,
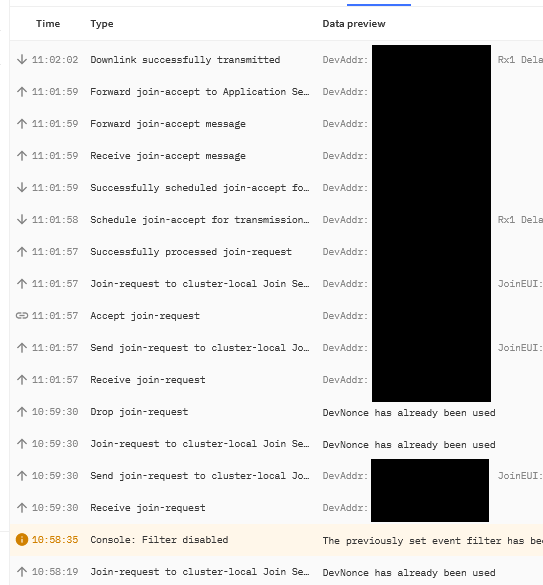
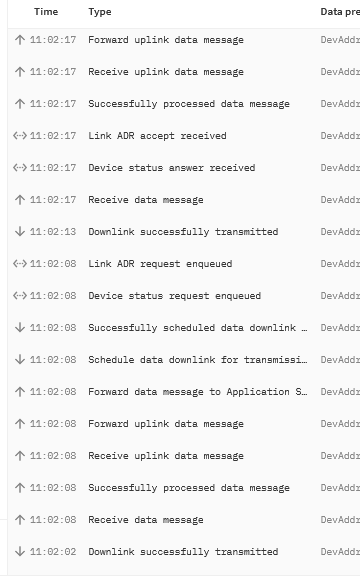
I am sharing my DevNonce has already been used experience in case its helpful. I am using a Browan MerryIot CO2 sensor. The batteries died 8 days ago. This morning I replaced the batteries, then triggered the device to do a rejoin by holding the button down for 5 seconds. The first time I tried that I got the error. I waited a minute or 2 then tried it again. After a minute or two data was flowing through TTN to my dashboard again. I’ve attached a couple screenshots.