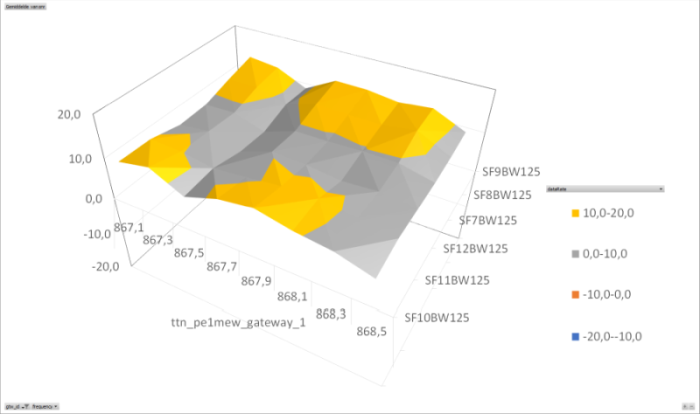
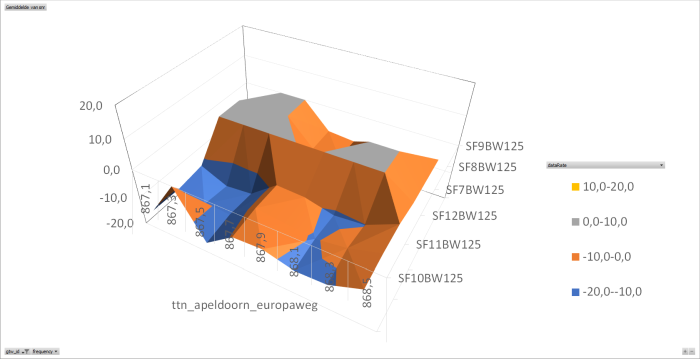
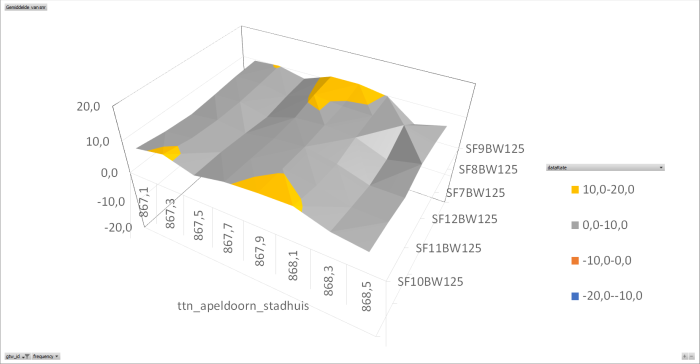
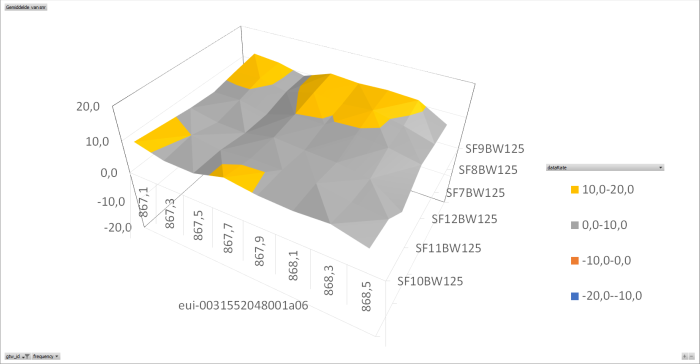
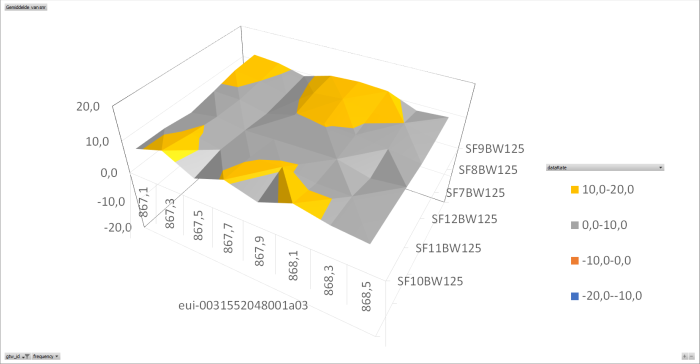
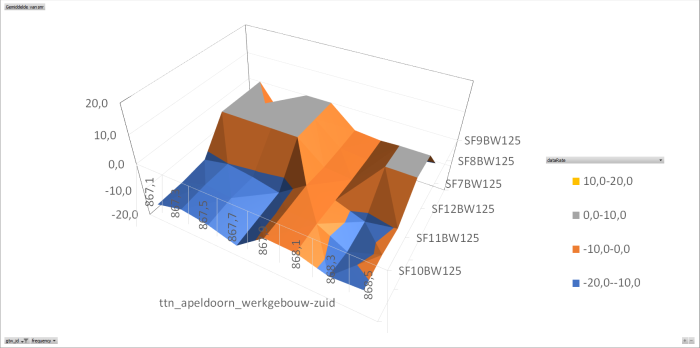
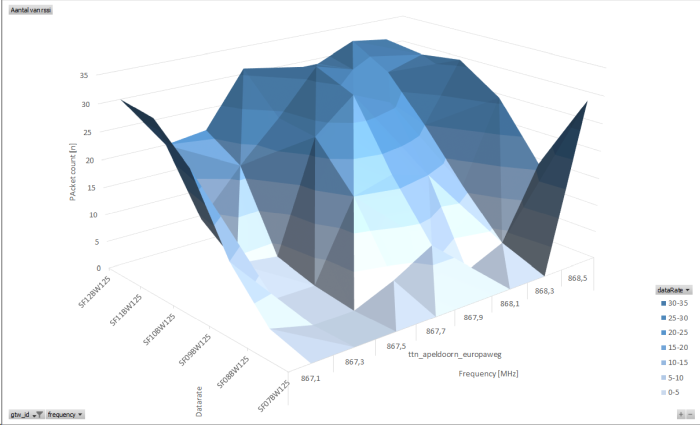
I have analysed the data I collected trough my beacon application. This application has one node that sends on all frequencies, all datarates over 24 hours. The data is collected and stored in a csv-file and than analysed using Excel. (later I will do this in a php implementation using a SQL database)
The collected data is than analysed per gateway on frequency per datarate per SNR. (I used the average SNR for all packets with the same frequency datarate pair). The result is shown in the following graphs.
At this time I have concluded that there is something wrong with two of the analysed gateways.
I have my thoughts on the interpretation of these graphs and I am curious to your thoughts.
Plese elaborate with me. Thanks!
First, you want to sort the SF’s numerically rather than alphabetically, so they actually end up in a consistent order
I used the average SNR for all packets with the same frequency datarate pair
That may be misleading if used in isolation. Consider that it could effectively “reward” a gateway which fails to receive weak packets at all, and “punish” one that receives good packets at very weak levels.
Perhaps what you should either do a parallel analysis on the overall number of packets received, or figure out a way to weight for that.
If you start trying to diagnose issues, look into the unique requirements of higher spreading factors - there’s a setting that needs to change at SF11BW125, and also frequency stability becomes more of an issue. Does your node have a TCXO?
Also consider that slower SF’s mean longer packets, which are more likely to suffer interference from something else. What do you know about the activity and siting of these gateways? An unfortunate reality is that a nearby node can blank out a gateway’s ability to receive weak signals on all frequencies and spreading factors - if someone jumps in at SF7 tens of meters from the gateway in the middle of your SF12 packet, they can likely break it, as even though these are theoretically orthogonal, the dynamic range over which that is true is limited.
So true I solved this already. (currently by adding a prefixing ‘0’ before 7 in SF7BW125. In the near future i will change to dataRate number instead)
This is technically true. However the chance that this phenomena occers over a longer period of time (interferring node at SF7 goes synchrone with the test generator) is extremely low and can therefore ignored in this approach.
Interesting thought. It is normal to look at success rate in communication networks. This could be a preselection prior to the analysis I do now. I do need to move to “known input - expected output” in my approach. I put this on the todo list.
I don’t think this is an issue because of the power of “big data”. I am not sure if this phenomena is of significance. How many nodes have TXCO?
RSSI is over a bandwidth of 125 kHz while SNR is the RSSI of the chirp signal relative to the noise floor in 125 kHz bandwidth. Because of comparing signals in two different banswidths we can have negative SNR. (we are actually comparing appels with pears)
This depends entirely on why these gateways exist, which I was asking what you know about.
If they exist to support their owner’s collection of very active nearby nodes (or adjacent to such a system, not necessarily having anything to do with TTN or even LoRaWAN) it could be that such an incident happens more often than it doesn’t.
I don’t think this is an issue because of the power of “big data”. I am not sure if this phenomena is of significance. How many nodes have TXCO?
Not sure what you mean there. I suggest reading up on the known need for a TCXO when using the slower data rates.
Ok, let me clear this out: All the gateways I examined are community gateways of TTN-Apeldoorn.
Yes I agree that in your definition the likelyness of “synchonous interference” is significant higher.
As you can see that is not likely the case here.
I agree that when you are forced to regular use of SF12 the need for TXCO’s increases. However. trough ADR any node can be forced to SF12 eventually. In the case of a single test node being used for this application/analysis and being the objective to test the gateway and not suffer form a poorly operating node it is good to use a node with TXCO.
In this case one single packet from one node is received by multiple gateways. From these gateways only 2 suffer from poor performance at low SF. If the node was to blame, all gateways would have shown the same result. Therefore the issue is not caused by the node.
Let’s put this on the todo list with low priority for fine tuning.
You’ve not actually provided any information which could support such a conclusion. If you are in contact with the gateway owners and could get a feed of all of their raw traffic to analyze - not just your nodes, not just TTN, not just LoRaWAN packets, then you might start to be able to say such. Though you’d still be missing the possibility of non-LoRaWAN users of the same band, broadband or power-conducted interference in those locations, etc.
However. trough ADR any node can be forced to SF12 eventually
Well, first in some parts of the world SF12 isn’t even a possibility as the headers themselves wouldn’t fit in a packet. But even where it is, just because the network server suggests it does not as a practical matter mean the node has to do so (though in the case of declining the suggestion it would probably be best to stop setting the ADR bit on uplinks, or only do so rarely to see if conditions have improved)
In this case one single packet from one node is received by multiple gateways.
It’s unclear if you are actually talking about the exact same packets vs. a statistical total. But if you are, it could be interesting to graph those across gateways, ie, use fCnt or time as an axis.
From these gateways only 2 suffer from poor performance at low SF. If the node was to blame, all gateways would have shown the same result. Therefore the issue is not caused by the node.
This does not necessarily follow - if the node is behaving in a way that is marginal, different gateways may respond to that in different ways.
Something very interesting to do would be to repeat your test, but temporarily install the same known gateway in each of these locations in turn, especially in the location of one of the “bad” ones.
Thank you for this discussion. It was what I hoped for when I started it and I do enjoy your elaborations.
Yes, you are right. I summarized the situation. i hope the additional information made it more clear.
Good news: I am managing all gateways. I am not there yet to setup streams to a centralized server collect all data and analyze it. This is one approach but I intentionally chose to start analysing a single node.
Currently ADR is not part of the analysis. The node is configured not to use ADR.
I can send you the excel with all information I used and which generated the graps for your understanding. If interested pse DM.
I will think about how I can generate the graphs of single packets over gateways. This might be included in the successrate approach.
The difference in frequency is odd, I’d suggest analyzing the gateway’s traffic that is not for this node (and maybe not even LoRaWAN at all) and see if there is something else going on. You could also consider putting a node in that location and borrowing the capability of node-side LBT code to take RSSI readings across the band. Worth trying another antenna on the gateway (or as previously mentioned another gateway in that location) too.