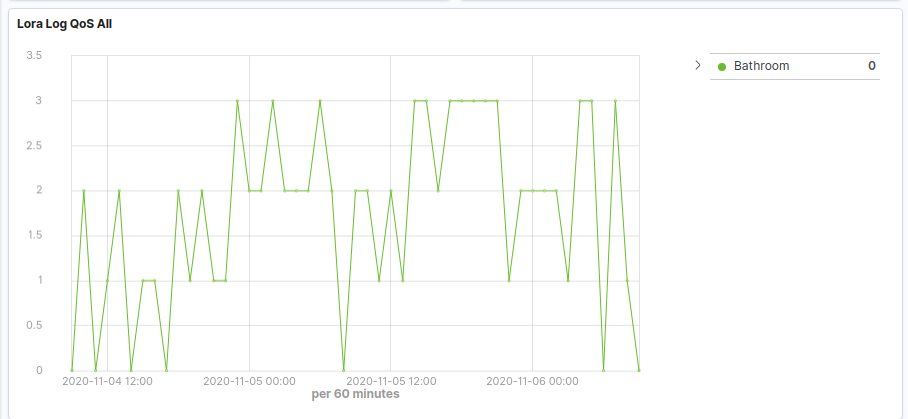
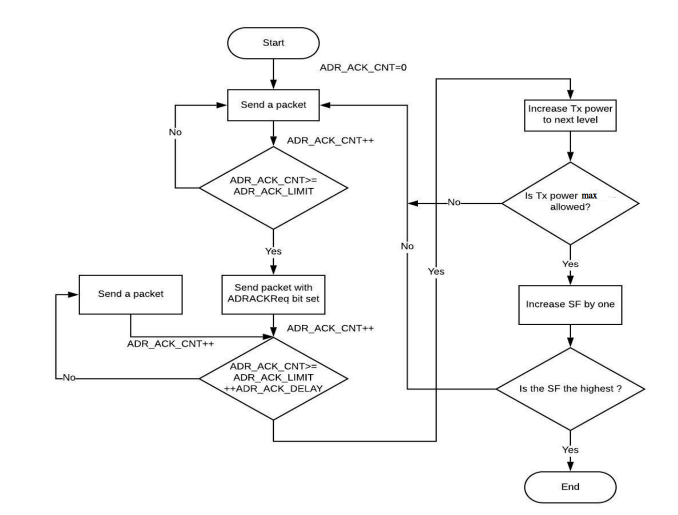
What we are seeing in the field is that ADR doesn’t seem to be doing a very good job of calculating what the optimal data rate is in order to establish a good QoS and minimise missed packets. In fact, we’re seeing a situation where ADR is being so a aggressive at increasing the DR (and reducing SF) that for some devices we stop receiving packets completely.
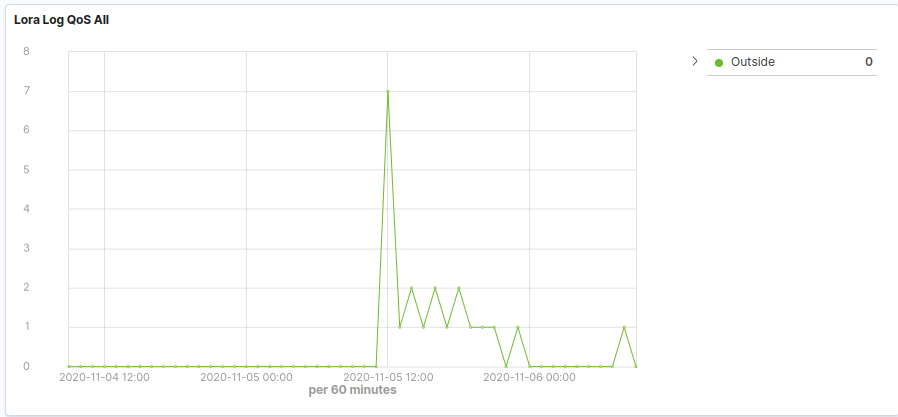
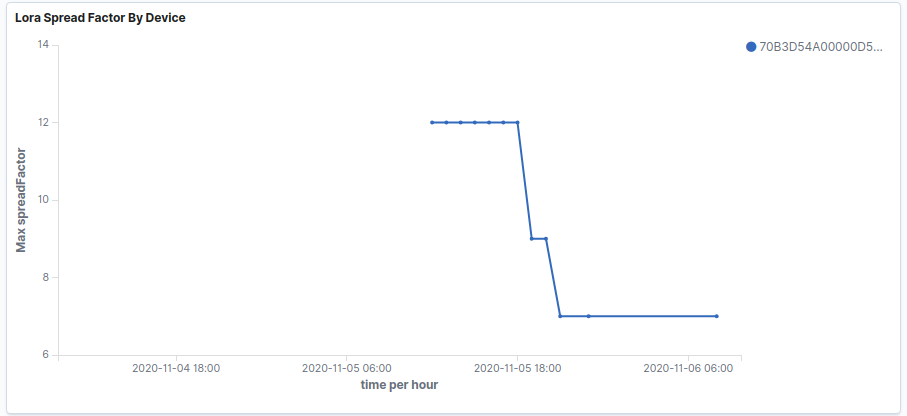
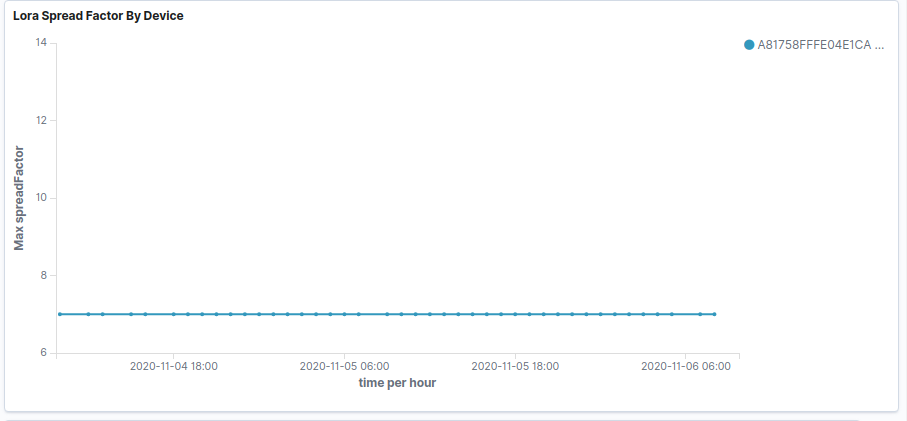
Above we can see that the device is working as expected for a period of time. ADR then kicks in dropping to SF9, at which point we start seeing missed packets. Subsequently ADR further reduces the SF 7, at which point the packets received flat line and we stop getting anything at all. This the scenario we are seeing if we start at a high SF.
The inverse of the scenario we see, is if we start at a low SF, ADR fails to increase the SF sufficiently in order for packet reception rates to be maximised:
On the above, the device sends every 20 mins, (so QoS graph should be showing 3 per hour in an ideal world). We can see that even though we are missing a good number of packets, ADR has failed to step in and raise SF to ensure a better QoS.
Has anyone else experience this type of result? Do we need more control over the ADR algo being used on the LNS in order to overcome these apparent limitations? We generally see much better results if we disabled ADR on the device and simply choose an SF manually but obviously this isn’t a very scalable solution
IIRC ADR relies on a larger number of received packets and wont adjust based on any one or even a few missed packets but rather will look at statistics say 20+ Tx’s received before commanding a change. This is usually managed on a per network level with each network setting own policy, which usually allows for some heardoom allownace on RX sensititivty to allow for signal strength variability (environment, weather, obkects etc.) - this might be set at say additional 6dbm above statiustical min. You can programme a node to make its own decisions to increase pwr/sf based on what it sees as success rate but that then relies on feedback from the network, which usually comes down to acknowledge/confirmed packets - a no-no at scale as system is engineered, architected and optimised to be heavily assymetric - lots of uploads with few downloads. Also a download renders a GW deaf for ALL users during that time and should be used very sparingly as considered anti-social to other users…who then start to see missed packets even as you look to solve your own problems
Can you advise what node and LoRaWAN stack you are using as others may have specific experience that can help…
Very nice graphs you made, I wish I had kept logs like that. I might from now on
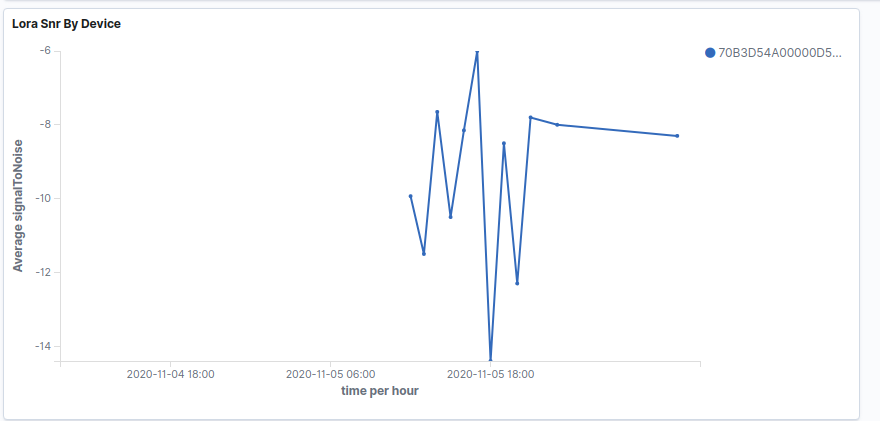
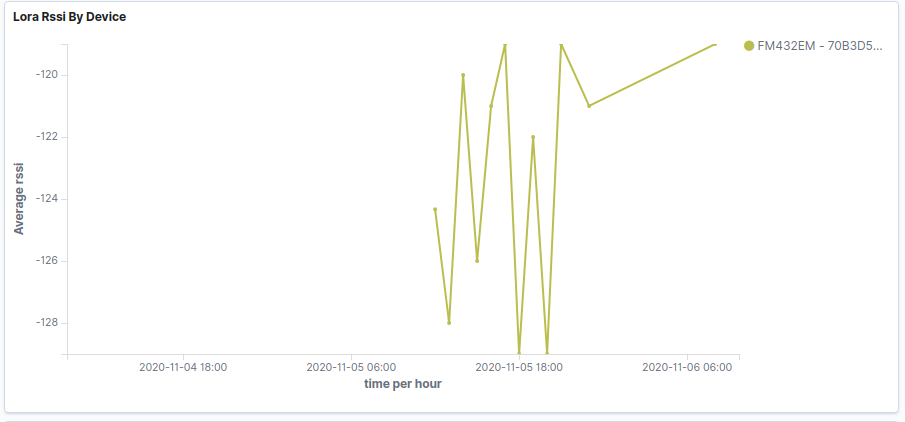
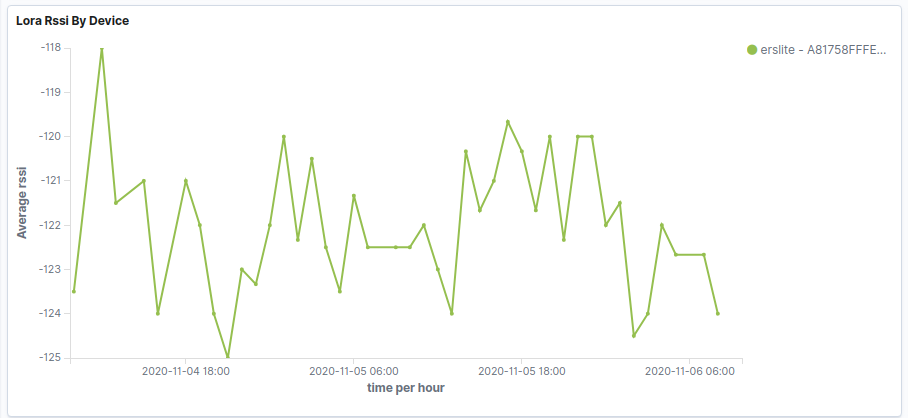
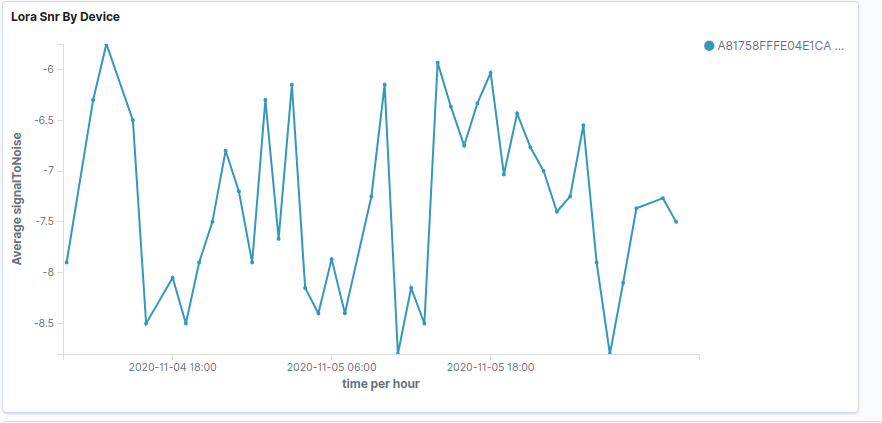
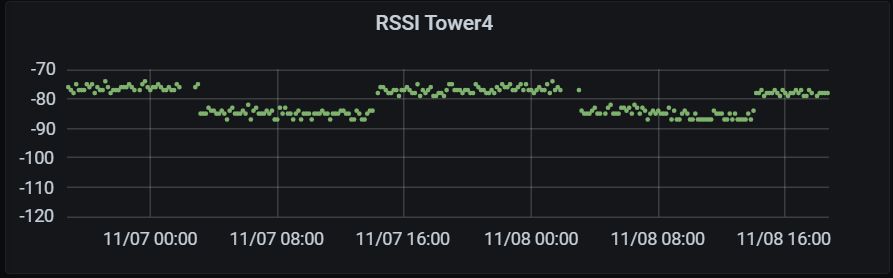
What I’m seeing with new nodes that are running for a couple of weeks now, is that the packet loss rate is quite high. Only about 30% of the data makes it through. RSSI varies a bit (-121…-106) and SNR from -10…+1.5 dB.
I enabled an MQTT log on all events (also downlink) and examined some of the ADR MAC commands being sent. You can decode the MAC command portion without needing the session keys using the decoder at https://lorawan-packet-decoder-0ta6puiniaut.runkit.sh/
All of the downlinks I’ve examined seem to command the node to DR5, or SF7.
Maybe this could be linked on the TTN page I mentioned before.
I am wondering if perhaps in my case, the RSSI/SNR is not really the problem. It might just be the gateway getting too much data and packets are colliding. This gateway is at > 50 m altitude and receiving data from a wide geographical area. In that case, allowing devices to use a higher SF / lower DR (longer air time) would only make the problem worse.
I think it would be very interesting if we could get a better feel about this, e.g. to know if gateways are struggling with traffic or not, how many downlinks they send, how many activations they get, etc.
Perhaps the problem of your gateway receiving the signals of your nodes is not caused by weak signals of the nodes but by other signals in the working band or nearby.
e.g. in EU868 the frequencies are used by many other transmitters. Nearby you have LTE and GSM. Especially if you have a “good” position of your antenna the input-stage of your receiver can be overloaded by the sum of the input-signals or it will reduce its sensitivity.
Use a spectrum analyser or a SDR-receiver to determine what is going on on the frequencies you use and nearby. Sometimes a selective antenna or a band-pass filter can make life easier for the receiver.
Would go further and suggest try a series of nodes (or reprogramming a single node for consistancy) at different fixed SF’s and also try at different Tx pwrs (say +14dbm, +10dbm, +3dbm, 0dbm, and -6dbm and see what statistics/success measures you gather from a decent fixed distance (100m/ 250m/ 500m?) will tell you a lot about local RF environment if you gather a decent qty of samples. Note be mindful not only of duty cycle but also TTN FUP - especially as you ramp SF’s
I have indeed tried the manual setting of SF and increasing the SF does resolve the problem and makes packet reception much more reliable, so I think we can be sure that if ADR stepped in and raised the SF it would improve the results I’m seeing, the problem is that it does not.
The network side of ADR should not lower the data rate (according to this Semtech document ):
Note: In the case where Nstep is negative and TXPower is already at its maximum the algorithm does not try to lower the data rate, because the end-device’s implements automatic data rate decay. The algorithm can only actively increase the data rate. Trying to lower the data rate leads to constantly oscillating values.
The node seems to be responsible for lowering the data rate.
(Increase SF == decrease data rate and vice versa.)
Thanks @kersing that paper is very enlightening, it seems clear that network adr does indeed only increase data rates but can increase or decrease transmit power. I think the next step in my investigation will be to check out the source for v3 and see how closely the implementation of adr matches that reference and also contact the manufacturer to understand their device adr implementation, as it feels like that is the key to understanding if and when Dr will be decreased
Ok I’ve been investigating this further and think I’m getting closer to understanding the behaviour which I’m observing with my end nodes.
I think I’m close to following the implementation of network adr used by the v3 stack. link_adr.go but am confused by the following
153 // Increase data rate until a non-rejected index is found.
154 // Set TX power to maximum possible value.
155 drIdx--
156 txPowerIdx = uint32(phy.MaxTxPowerIndex())
Surely drIdx-- decreases the date rate, rather than increase it as per the comment. Say current drIdx is 5 (SF7/125kHz) and I decrement it by one, I get a drIdx of 4 (SF8/125kHz) which is a lower datarate not an increased one.
The behaviour I’m seeing in real life is an increase in DR though (lower SF), so I’m obviously missing something obvious here and I’m bound to feel stupid when this is explained, but its worth it in order to improve my understanding! If anyone could shed any light, that would be most appreciated.
I can confirm your assumption. This node is about 500 metres from the gateway and running at constant Data Rate but the RSSI increases and decreases. Therefore the node must be increasing and decreasing Tx power.
Ok, I’m just going to assume that I misunderstand the drIdx-- and assume that it does increase the DR as per the comment as this is also what is described in the link with @kersing kindly supplied. With this in mind let me try to outline what I’ve understood the ADR behaviour to be for both the network and the device.
Network
After sampling for a number of uplinks, the network will calculate the link budget based on the maximum SNR of the sampled frames and a “margin”. If excessive link budget is detected, data rate will be increased, lowering SF. If insufficient link budget is detected, then transmit power will be increased, up to the maximum, but data rate will not be changed.
End Node
If after a certain number of uplinks there is no downlink response of any kind (not just ACK but any other MAC command), transmit power will be increased. Once transmit power reaches the maximum, then SF is increased.
Observations
My real world observations match with the above. If I deliberately ensure that uplinks do not make it to the LNS (for example I enter a wrong packet forwarder address for testing purposes), I can see that my end node does indeed ratchet SF one higher, for 1 uplink, every 7 uplinks in the following fashion e.g.
SF7 x 7
SF8 x 1
SF7 x 7
SF9 x 1
SF7 x 7
SF10 x 1
etc
Implications
If a end node transmits every 30 minutes and starts at SF7, then SF will not be increased on the end node unless no downlinks are received from the server for 3.5hours!
This means that there is absolutely no mechanism in place to improve intra-hour QoS/Packet reception rate, on either the server or end node. If in a two hour window, 1 uplink is received by the server and there is 1 downlink, than SF/DR will not be changed, even though we have lost 75% of packets.
End node ADR is really only there to allow the end node to reestablish connectivity in the event of complete connectivity loss, rather than to tune for QoS
This would imply the best approach for QoS optimisation would be to ensure that all end nodes transmit at SF12 initially and rely on network ADR to “tune this down”, as there is really not any “tune up” mechanism in place rather than in a the scenario of a rather lengthy loss of connectivity. This obviously seems quite inefficient and will pose scalability challenges during high density deployments of new nodes.
Lets say that the connection is reestablished at DR 2, if the SNR of the previous uplinks received by the server results in a link budget calculation that sets DR 5, the device will immediately be advised to switch back to DR5, which could mean that connectivity is lost again, this doesn’t seem desirable, are there allowances for this? Does the previous uplink buffer on which ADR is calculated expire in some way?
Request for Comment
I’d really appreciate if anyone could either confirm or refute my understanding and observations. If confirmed, then I can’t help but feel that we’re missing a key mechanism that is really important in many real world use cases. Sure, ensuring an end node is able to re-establish connectivity in the event of say a GW going offline and the next-nearest only being reachable at a higher SF is critical, but to my mind, there is a clear requirement to establish the optimal SF for day-to-day operation. Choosing to start at the highest SF and working down seems like the only feasible approach to achieve this, am I correct in this line of reasoning?
Other details
Gw: RAK7429
LNS: Things Stack v3
End node: Elsys ERS