Hi, was currently testing 3 Class C end devices on the V3 stack. These have been operational for just over a month but lost the ability to join about 9 hours ago. Is anyone else experiencing this problem? Thank you.
1 Like
Yes.
I’ve seen no brokered packet forwarding from V3 registered sensors via V2 gateways since around 23:50 1st May
On a variety of application, sensor and gateways
1 Like
E.g.
Here’s 26.0b.62.01 not seen since 9 hours ago.
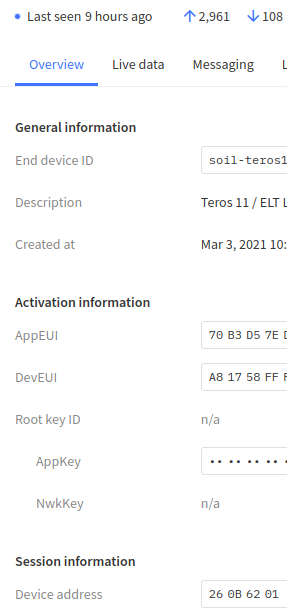
But here it is being passed through its local gateway.
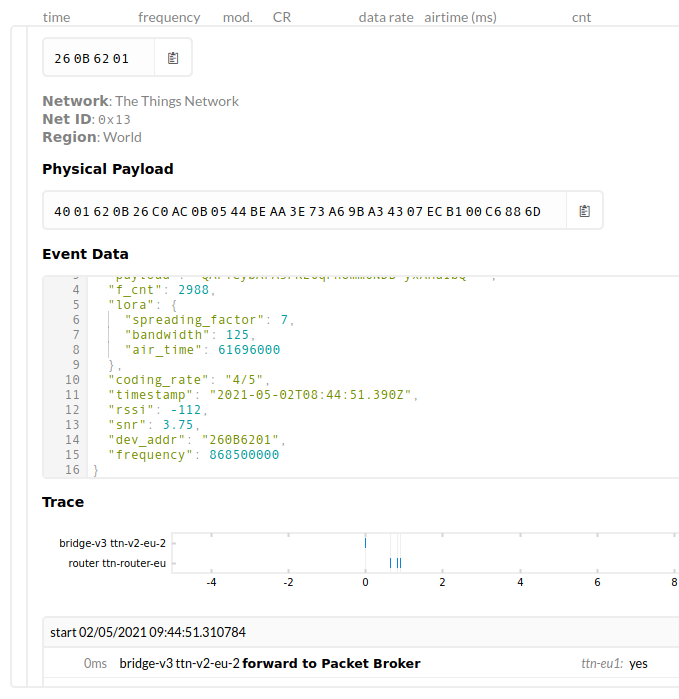
1 Like
Yes, I’m having exactly the same problem. Thanks for letting me know.
1 Like
I was just about to post the same thing.
I’m UK (EU cluster) by the way.
I’m in Durban South Africa. Using the same cluster.
intercontinental sad face 
2 Likes
No-one from TTI support reads this, so it’s just a pity party.
Have any of you posted a message on Slack #ops???
1 Like
Thanks - was wondering where to post, scuse the ignorance!
A few have already posted in #ops so it’s just a case of waiting for TTI to become sufficiently caffeinated.
I realise I was a bit blunt but I’ve been burning hours like crazy of late on here.
Debugging these sorts of situations is becoming problematic - turning off my v3 gateway to see what happens is not a good move for the test devices that rely on it - I need a house with multiple cellar rooms that can have Faraday Cages in - can double as student accommodation.
4 Likes
I have the same problem, I test two end devices for 2 months without failures in the V3,
today at about 1 o’clock both devices no longer transmit any data to thingspeak. My gateway is still V2.
In the trafic-windows of the I see the join request from my device.
1 Like
Similiar problem here (close to Berlin).
All data from my V3-sensors is received via a V2 gateway and arrives in the console.
But then the data is not forwarded to V3 - the console says “router-ttn-router-eu drop reason: nobrokers”
The last transfer happened at 1:53 am local time today, that should be 23:53 pm UTC on may 1st.
It’s a v2 wide issue that’s not geographically focused so no point adding a #MeToo
IMHO its always embarrassing for a service provider to learn about an outage from its users…
…and still no entry on the “past issues” page… The Things Network Status - Incident History
True.
But there is no evidence that this was the case. Just no feedback because the TTI crew are focused on v3. This is the current new normal whilst we go through this transition period.
But also consider that TTN is a service provided for free so maybe expectations need to be different than for one with a paid service.
What ever the underlying problem looks to have been resolved around 12 CET yesterday - no doubt someone hit the PB server with a baseball bat or the cleaner put that disconnected network cable back in 
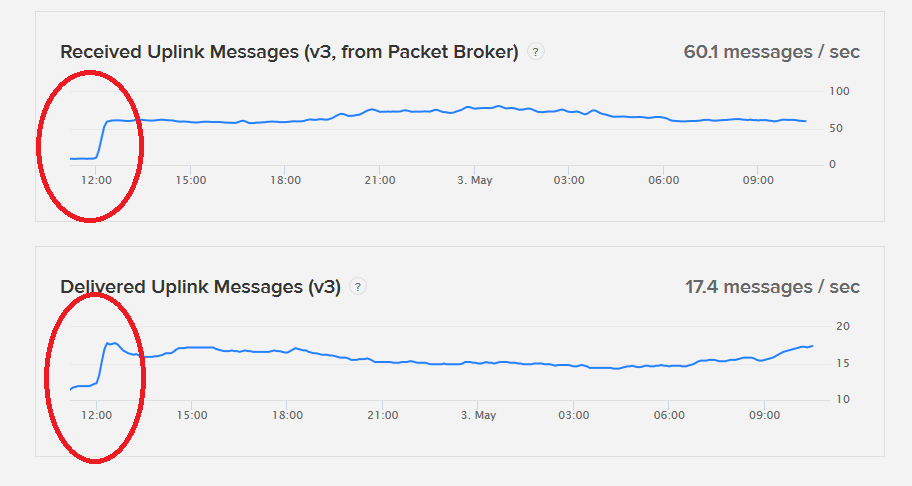
Reports on #ops channel suggested some affected users were indeed seeing traffic return after that. If you still have a problem there may be another issue specific to you/your devices/your account/? is it resolved?
A good way to see if there is a current or recent issue is to check the stats charts on the status page vs looking for a narrative on the history pages - if its current its news not history If its history has someone bothered to write it up (esp at weekend on a free service! ) https://status.thethings.network/
1 Like
Just packing up for the night and happened to check status and see what may be the start (in last 30-40 mins) of another problem? Interesting that there is a corresponding ~30% uptick in V3 traffic around same time… no issues raised on Slack yet and no posts to forum for people with problems or asking for help so may be nothing…will look again in the morning!
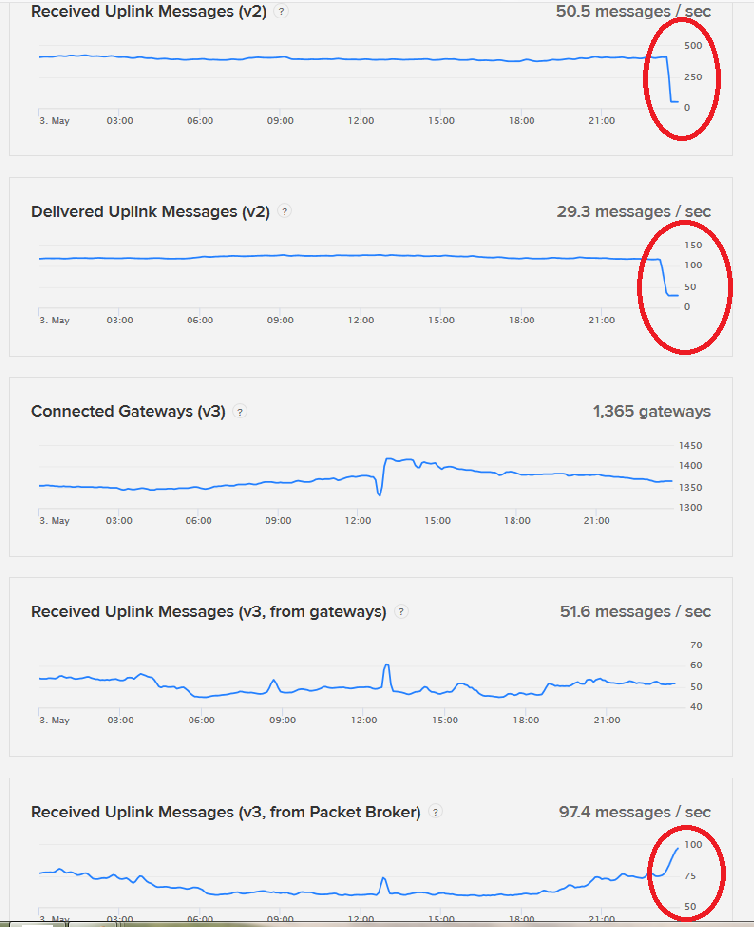
Yep, there was a problem so anyone missing data overnight (EU time zone) can see why - now resolved per status message below
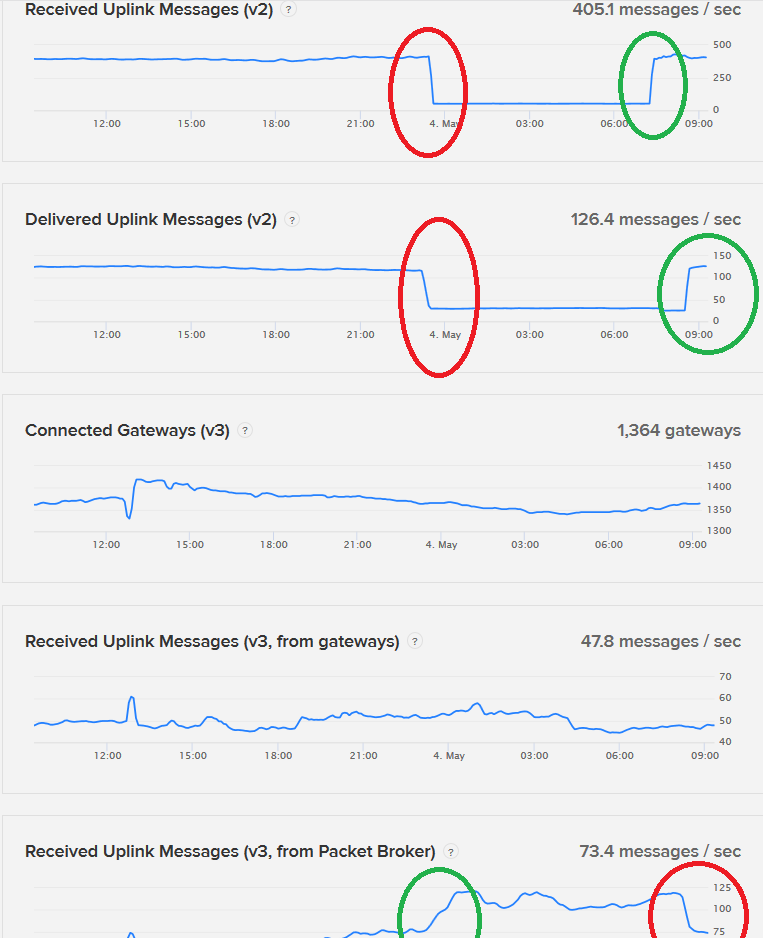
May 4, 2021
Resolved - This incident has been resolved.
May 4, 10:22 CEST
Update - Our metrics show that traffic is flowing again. We have re-enabled the MQTT API and are monitoring the system.
May 4, 10:01 CEST
Monitoring - We discovered that the router is the failing component at the beginning of the investigation. We recovered the router quite easily, but the handler crashed (similar to a previous outage) and took a while to recover.
We have temporarily disabled MQTT ingress and are monitoring the situation.
May 4, 09:28 CEST
Investigating - We are investigating an outage in the TTN V2 Cluster
May 4, 08:41 CEST
Interesting to see that as V2 traffic dropped there was corresponding uptick (and subsequent fall back on fix) in V3 traffic…
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.