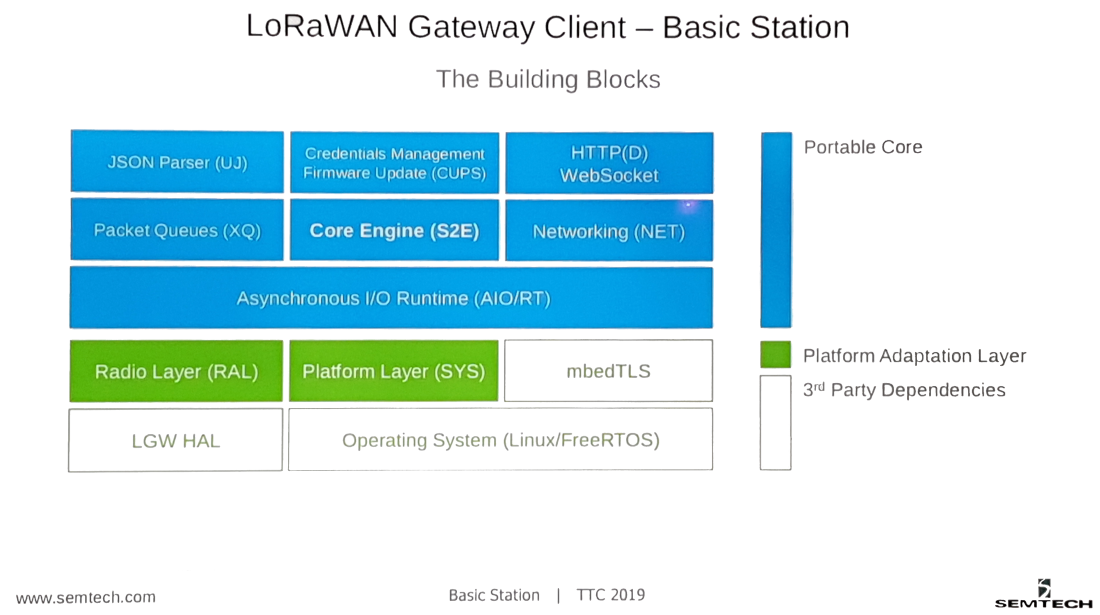
During Semtech’s Basicstation (workshop) presentation held at The Things Conference last January, it was mentioned that Basicstation itself is open source, but the implementation of the ‘Platform Layer’ and ‘Radio Layer’ building blocks for ESP8266 (used on the TTIG) are closed source.
This makes availability of an open TTIG project on Github less likely.
1 Like