Thanks for the response. I’m always wary of the “too close” issue, but I don’t think that’s relevant here. There’s at least 8 metres gap through walls, ceiling and roof, and RSSI is around -60dB to -80dB. SNR is typically at least 10 though. And as you suggest, the logs suggest that’s not the issue.
How can I determine whether the packet is destined for the RX1 or RX2 window? I can’t see anything in the packet format that specifies that.
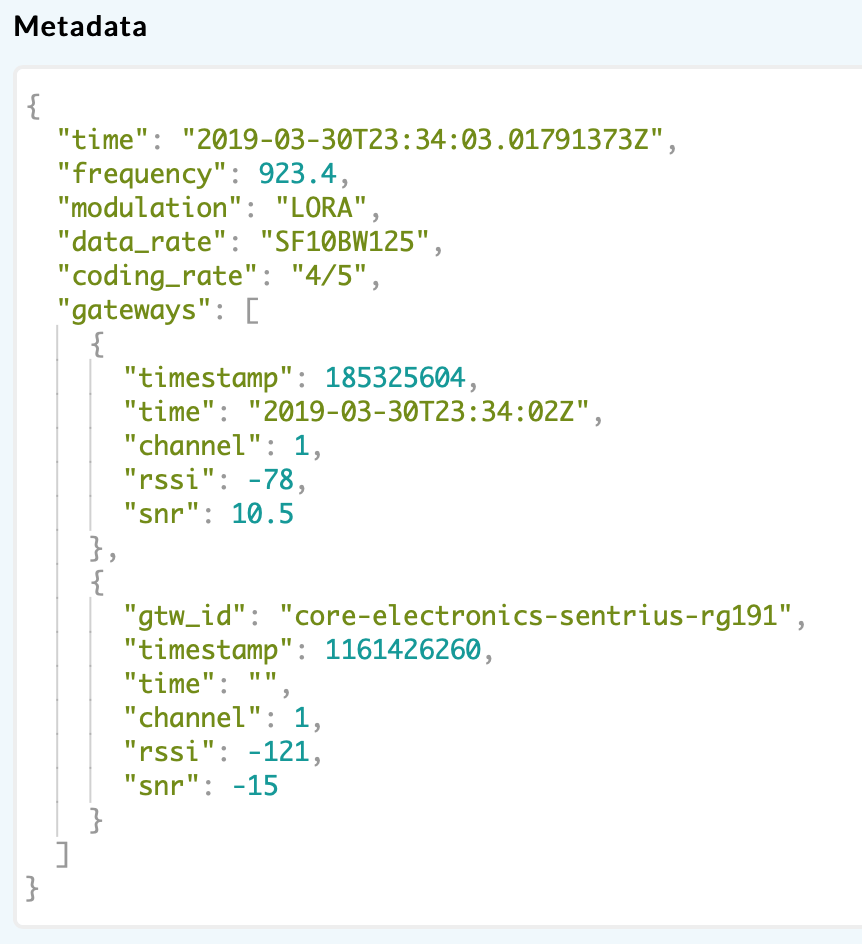
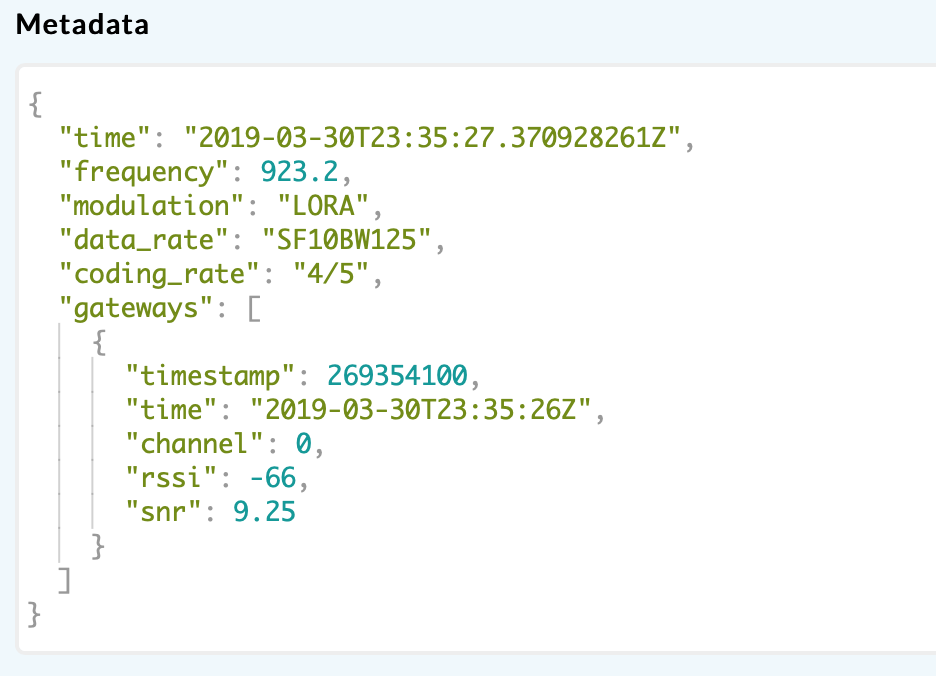
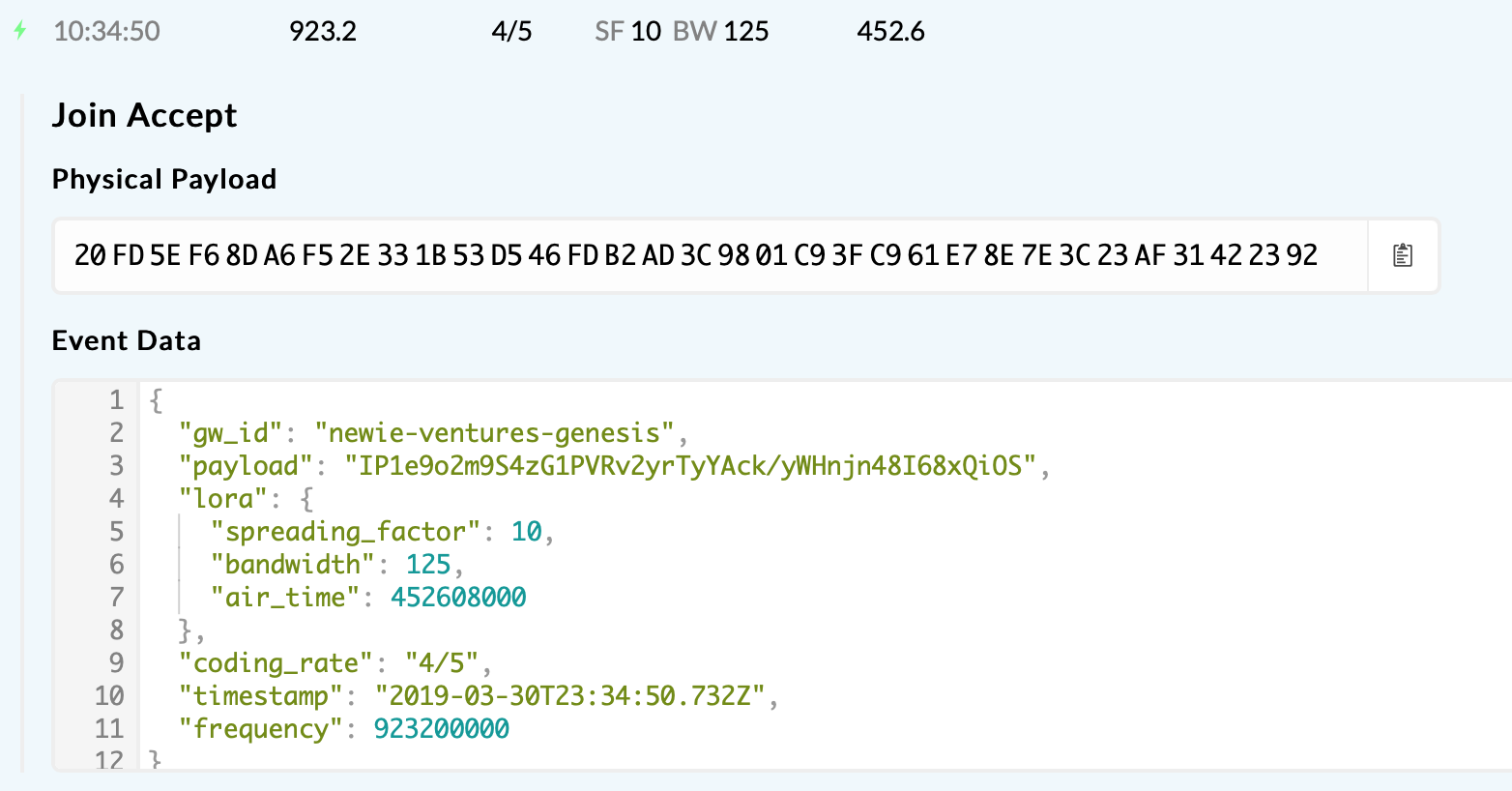
I’ve logged a couple more examples of failure/success. Significantly, this failure example occurs on the same frequency:
Console join-request:
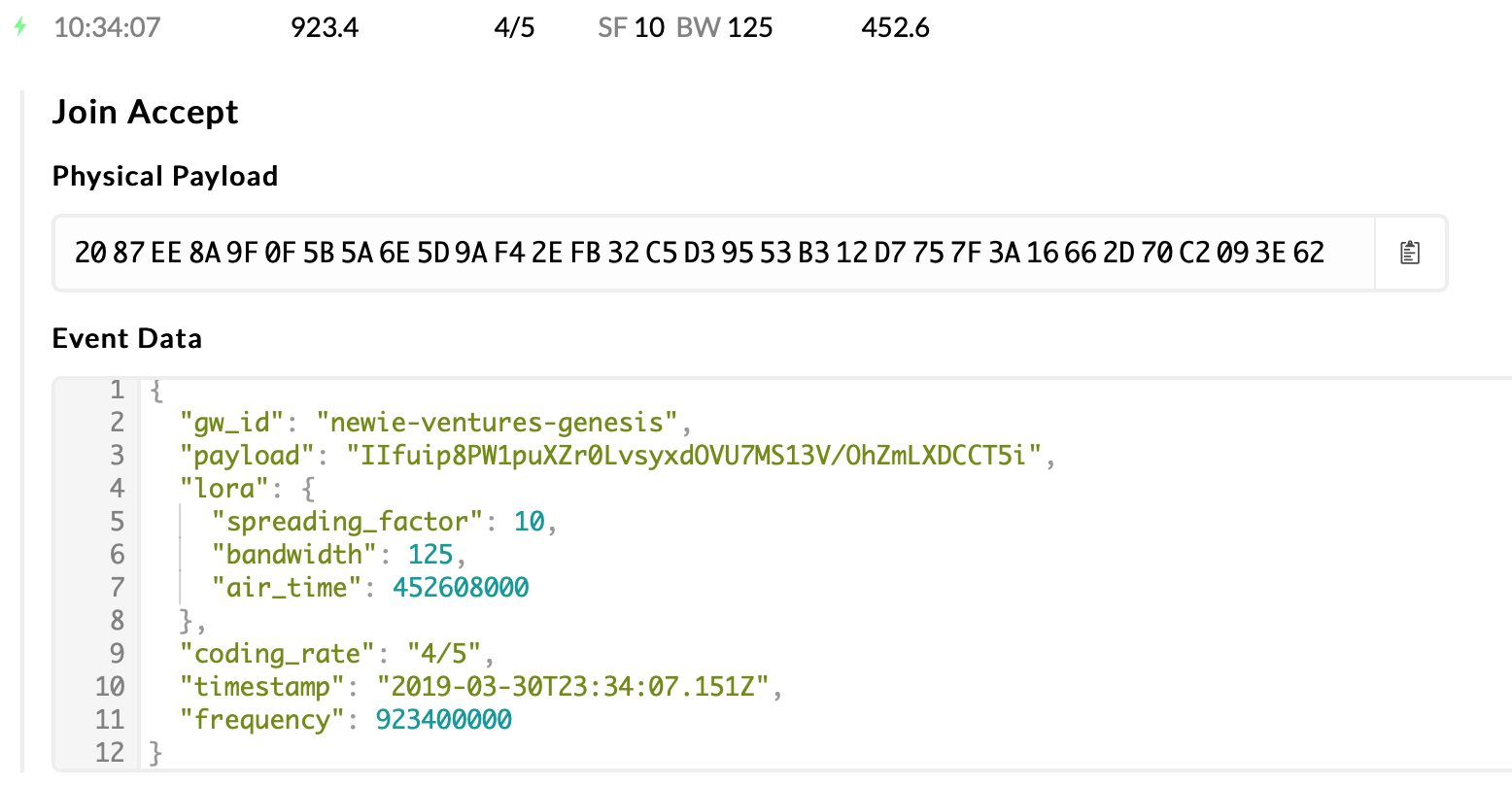
Console join-accept:
Gateway log:
|2019-03-31 10:34:03|lgw_receive:1165: FIFO content: 1 8f 2 5 17|
|---|---|
|2019-03-31 10:34:03|lgw_receive:1184: [1 17]|
|2019-03-31 10:34:03|Note: LoRa packet|
|2019-03-31 10:34:03|10:34:02 INFO: [stats] received packet with valid CRC from mote: D000C0B7 (fcnt=46037)|
|2019-03-31 10:34:03|10:34:02 INFO: [up] TTN lora packet send to server "thethings.meshed.com.au"|
|2019-03-31 10:34:07|10:34:06 INFO: [down] TTN received downlink with payload|
|2019-03-31 10:34:07|10:34:06 INFO: [TTN] downlink 33 bytes|
|2019-03-31 10:34:08|INFO: Enabling TX notch filter|
|2019-03-31 10:34:08|66.d9.99.b.58.1d.8d.9.0.9a.21.10.0.8.0.0.20.87.ee.8a.9f.f.5b.5a.6e.5d.9a.f4.2e.fb.32.c5.d3.95.53.b3.12.d7.75.7f.3a.16.66.2d.70.c2.9.3e.62.end|
So I’m back to square one - it seems for some reason the node is simply does not receive the join-accept sometimes. And I can’t see what that reason is.
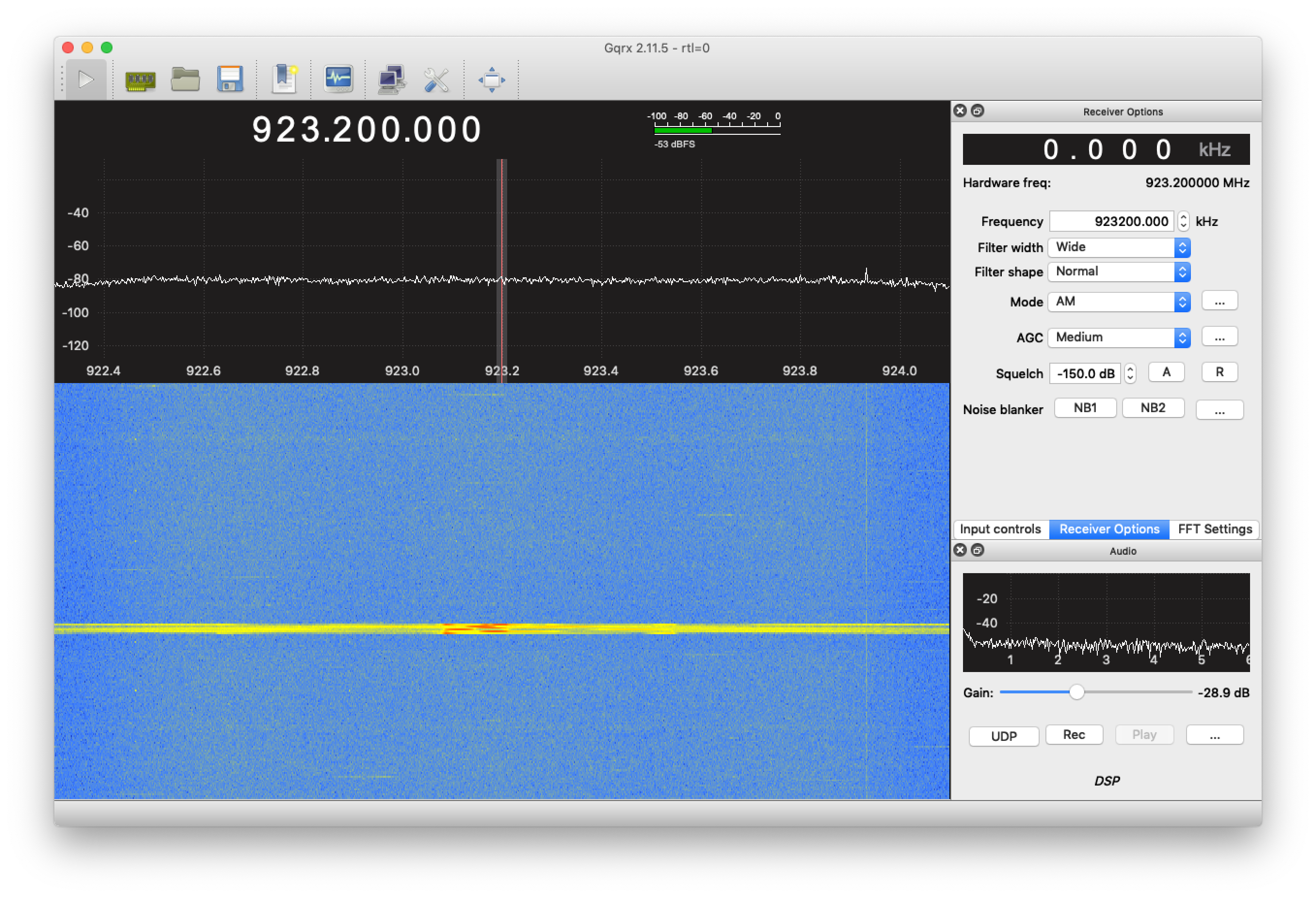
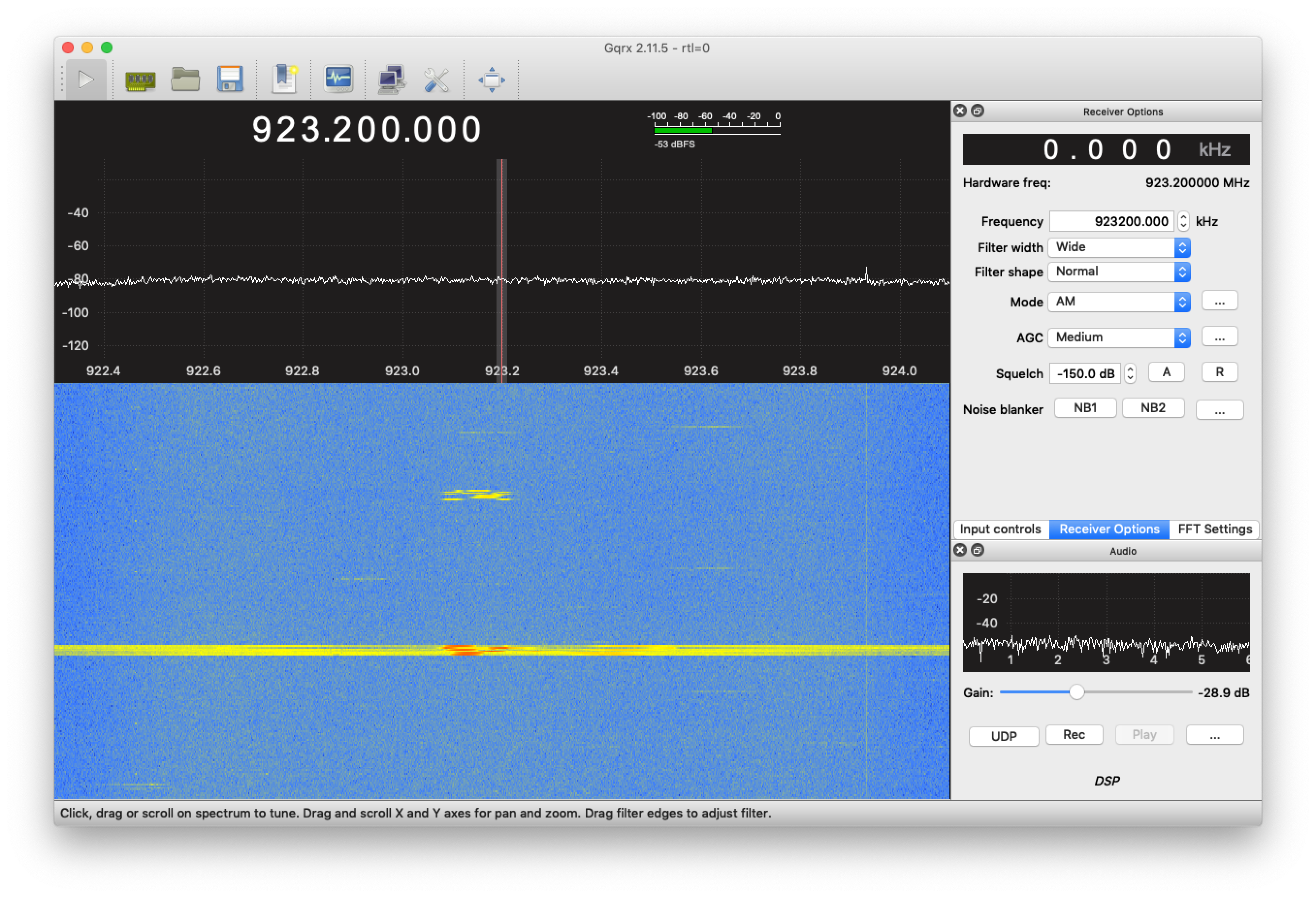
Logs were giving me nothing, so I cracked out the SDR. Hallelujah!
See if you can spot the difference.
Failure:
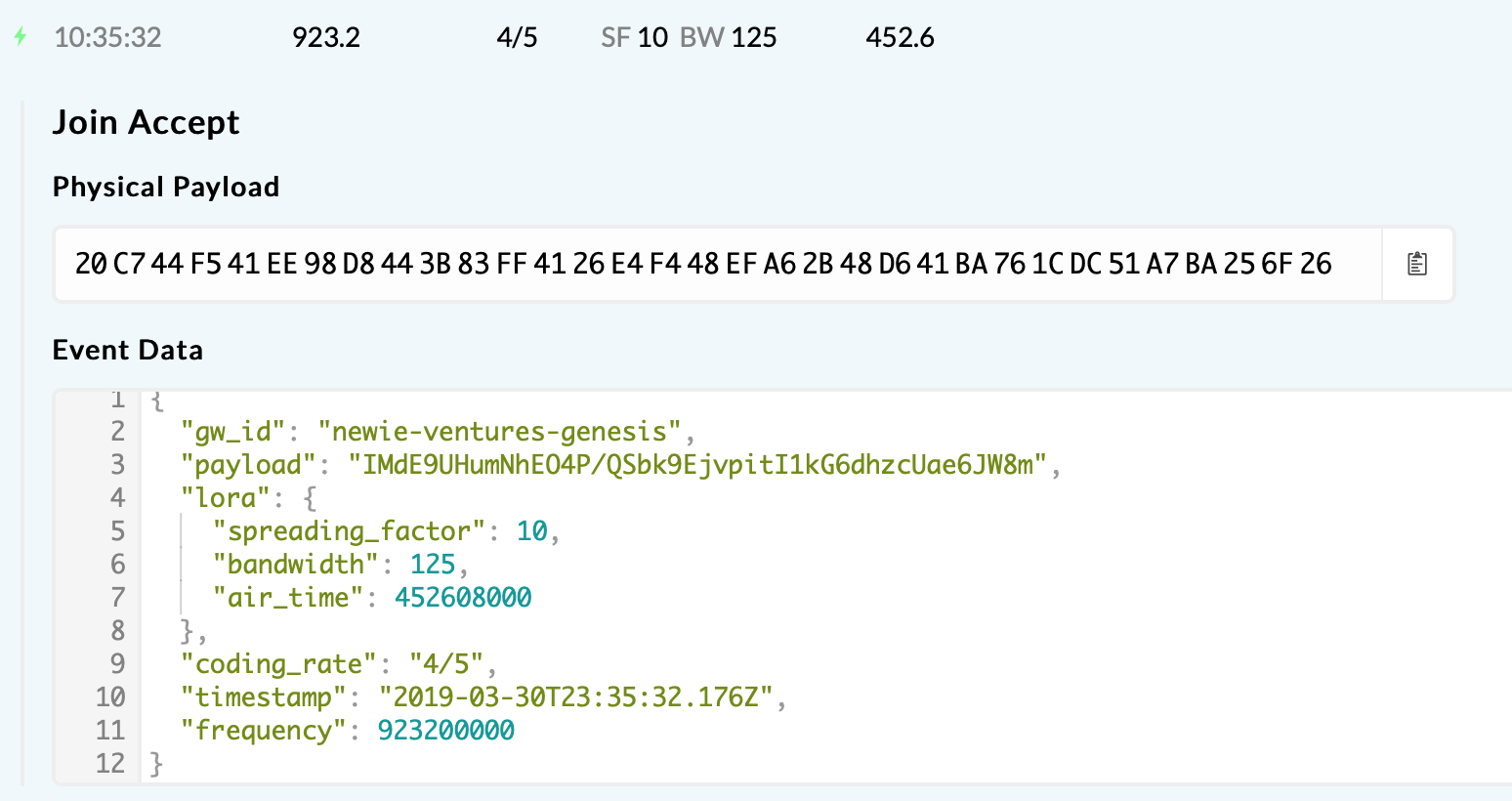
Success:
In the failure scenarios, the join-accept is simply not transmitted over the air! Everything else appears to be the same, so this maybe an issue in the Conduit we’re using as a gateway.
Okay great. What more can I do to diagnose why the Conduit running MP Packet Forwarder is often not transmitting the join-accept over the air?
I note in the logs above that 2019-03-31 10:35:33 10:35:32 WARNING: a downlink was already scheduled, overwriting it... often appears. Could the downlink be being scheduled rather than transmitted?
I tried adding "logger": true to the .conf file but it didn’t seem to make any difference.
If we can crack this it seems we’d be on the verge of cracking many more mysteries, like:
Anything that needs to be transmitted is scheduled first in the jit queue.
That isn’t a good sign, it means there is still a packet that should be transmitted queued on the concentrator hardware when the next packet scheduled for transmission is due and the later overwrites the first.
Btw, why link ‘random’ messages regarding join issues like they are all related?
I’m a regular on the MultiTech forums, but I can’t yet formulate a good question. I think I need to get clearer on the issue. Do you think there’s a useful question to ask?
Maybe. I doubt it, because this can occur from a fresh start with little previous gateway activity, but I can’t be sure. Anyway to check?
Great info. Anything I can do to diagnose why the scheduled packet didn’t get transmitted?
Out of the dozens I read, these all looked to have the common features of 1) unsolved, 2) join-accepts not being received, 3) some combination of Conduit, TTN and mDot. In fact, most of them report symptoms along the lines of “join-accept sent by server but not received by node” which is at the heart of the issue here. Whenever I research issues like this, a large part of the effort is in sorting through previous threads looking for commonalities. I really appreciate it when people go to the effort of amalgamating them so efforts can be combined. Given how common these issues are, I was encouraged to think there might be a common cause that could shed light on them all. Do you not agree?
Given how disparate the technologies involved are and the age of the messages (message 1: MultiTech 2016, message 2: Kerlink 2017, message 3: RPi, RFM95 and LMIC, message 4: MultiTech 2016) I don’t see a lot in common except for the description.
Keep in mind the software evolved a lot over the last two years so any information from before the start of 2018 is as good as obsolete because the software involved is no longer being used. (Unless someone is using old software against better judgment)
For the MultiTech forum you will need to run their software stack. That might be a good idea for debugging purposes anyway.
What hardware are you using? Does your hardware support Listen Before Talk because the AS923 frequency plan specifies LBT. LBT might be a cause data is not transmitted if the gateway somehow thinks the channel is not free for transmission… I don’t think the current software build will log anything if LBT prevents transmission. Not sure any logging for this can be enabled as I think this is all done on the concentrator.
LBT is the biggest difference I am aware of between AU915 and AS923 (apart from the obvious difference in frequencies).
These symptoms are exhibited on a variety of hardware, but this investigation has been with a MultiTech Conduit MTCDT-H5-210A with MTAC-LORA-1.0 card which is of the USB variety (though I haven’t noticed a difference with MTCDT-246A/247A versions) as the gateway and an mDot as the node.
This gateway does not support LBT, so we have to manually set lbt_cfgenable to false to get the AS923 plan from TTN to work.
Anything else I can do to reveal more information at the point the join-accept is scheduled?
Hmm, well I have another interesting data point now:
These results were repeatable on two different Conduit MTCDT-H5-210A with MTAC-LORA-1.0 cards (USB variety).
Today I was unable to repeat the symptoms on a newer Conduit MTCDT-247A with the MTAC-LORA-H card (MTAC-LORA-1.5 SPI versions)! I had 100% successful join-accepts out of a dozen or so attempts.
Interestingly this is with the original 0.31 FPGA firmware and without enabling LBT, so the MP Packet Forwarder config is the same.
So this is surprising, but is looking like an issue with the concentrator on the USB version of the Conduit LoRa cards? Can anyone back that up?
Yes this is sounding all too familiar :). We had some horrendous downlink issues about a year ago and I never really found the cause. Our joins are pretty consistent now, mostly succeeding on the first attempt. Occasionally I’ll see a device try 2-3 times to get a successful join, but this is the exception.
A number of random thoughts from me in case it helps:
We use the default v31 FPGA firmware and manually disable LBT in global_config. It’s not required in Australia. It’s nice to have, and we’ll get it enabled one day, but I haven’t had time to look into it further.
Test with the built-in Multitech lora-packet-forwarder just to be sure that the issue can’t be traced to mp-pkt-fwd
Update the conduit firmware to eliminate that as a source of issues, if you haven’t already.
For the older USB LoRa cards (MTAC-LORA-1.0), we’ve succeeded in getting stable downlinks on a group of gateways using Multitech’s gps-pkt-fwd. This is similar to basic-pkt-fwd, but apart from sending GPS location, also sends status messages to the gateway. basic-pkt-fwd, being based on an old version of the spec, does not send status messages, so you’ll see some large “last seen” values on the TTN Console.
It’s really hard to tell from logs/messages whether a downlink was sent on RX1 or RX2 or when a queued downlink is overwritten. I believe TTN V3 will be much better at communicating this.
I’ve long suspected that an issue with RX2 was causing our downlink issues. I don’t really have any evidence to back up that comment so I may be completely wrong, but I don’t think I’ve ever seen a downlink on RX2 on my SDR - even after trying to force an RX2 downlink. Also I have less hair as a result of diagnosing downlink issues and I’m pretty sure that’s accurate
Just want to throw out three key ideas I’ve been using for debugging a little bit different setup; fortunately one that uses MQTT in between the gateway and network which makes some of this a little less hackery than it would be in a TTN setting, though it should still be possible there.
I make my node firmware serial debug output tell me what frequency, SF, etc it is transmitting and receiving on, and I capture this to logfiles I can search back through and see if it matched what the gateway reported or was told to do.
I record all RX reports and TX requests going into or out of the gateway (this is easy with MQTT, with other schemes you would need to build some interception logic into some component, or man-in-the-middle the servers). Want to know if a reply is RX1 or RX2? Check the rolling microsecond timestamp of the transmit packet vs. the packet it is replying to. Similarly it should let you see what other transmit request caused a temporal collision. You should also be able to match join accepts in time/frequency back to their join requests which contain the node identity. Granted this is also premised on everything interesting happening through a gateway you control, but for pre-deployment testing putting the node in a metal box will typically reduce the range enough to have that happen.
While tuning a tricky case, I blipped a GPIO during the node receive window, put one scope or logic analyzer probe there and got the other probe on the gateway’s transmit LED which is ultimately driven from the SX1301. Nothing like literally capturing the temporal lineup of TX and RX on a storage scope.
Thank you for those excellent replies. Those nuggets of discovery really do help track this issue down.
After another solid weekend of experimentation I have some more clarifying data. Really hard going this, but the picture is slowly becoming clearer. In the following table, “works” means with the latest software available today unless indicated, downlinks are >80% reliable for “YES”, <20% reliable for “NO”. There was no in-between.
For the AS923 scenarios I tried both AS1 and AS2 with no change. For the gps-pkt-fwd scenarios I even tried the TTN global_conf.json and for the mp-pkt-fwd the MultiTech global_conf.json, all with no change.
There was two major challenges that made the going tough - once you know them they are not a problem, so for posterity:
gps-pkt-fwd is the forwarder that gets run by MultTech’s Lora Packet Forwarder if the config file has fake_gps set to true. gps-pkt-fwd (and its non-gps brother, basic-pkt-fwd) are “Legacy Semtech Packet Forwarders”. That means they use UDP on port 1700, and require a gateway in TTN’s console explicitly for the legacy forwarder (click the “using Semtech forwarder” checkbox and note the gateway ID will be eui-xxx where xxx is the gateway’s EUI). Authorisation is not supported, so the gateway key is not used. The global_conf.json files provided by MultiTech are all you need, provided you override gateway_ID, server_address, serv_port_up and serv_port_down, with the gateway’s EUI (use mts-io-sysfs show lora/eui and remove the colons), which ever router you want to use, 1700 and 1700 respectively. Oh, and to enable gps-pkt-fwd also add "fake_gps": true,"ref_latitude": -x.x,"ref_longitude": x.x,"ref_altitude": x where the x's are appropriate numbers.
/etc/init.d/ttn-packet-forwarder stop doesn’t. I think at one stage it relied on mp-pkt-fwd killing itself if /var/run/run-lora is missing, but that doesn’t work for me at the moment. Judging by the source, it just responds to HUP by rotating the log file. Maybe my install is hosed, but I had to remove the HUP signals from ttn-packet-forwader (the -s 1 and -1 flags) so the start-stop-daemon and killall calls would actually kill mp-pkt-fwd.
So these signs are pointing to an issue with the new mp-pkt-fwd and the old MultiTech LoRa cards. Further investigation is necessary to see if it’s something to do with the rx delay.
One more tidbit before I hit the hay. Here is the start of the log file when gps-pkt-fwd boots up:
*** GPS Packet Forwarder for Lora Gateway ***
Version: 1.4.1
*** Lora concentrator HAL library version info ***
Version: 1.7.0; Options: ftdi sx1301 sx1257 full mtac-lora private;
And here is the equivalent for mp-pkt-fwd:
20:28:15 *** Multi Protocol Packet Forwarder for Lora Gateway ***
Version: 3.0.20
20:28:15 *** Lora concentrator HAL library version info ***
Version: 5.0.1; Options: ftdi;
No it didn’t. It relied on SIGHUP not being used to cycle the logfile (introduced in a newer version of the software and I simply forgot to update the script).
You can substitute the 1 by 2 or 15 (also the default if none specified) to fix the script.
Could well be. I had to apply a patch to get the HAL to recognize the older MultiTech fpga firmwares. There might be a breaking change for 915MHz in there (I haven’t seen any release notes for the fpga firmware so I don’t know the changes) Also hard for me to test being in EU868.