Always using the same setup based on “The Things Node” I investigate the behaviour with different SF initial setup obtained defining the “sf” with the method:
TheThingsNetwork ttn(loraSerial, debugSerial, freqPlan, sf);
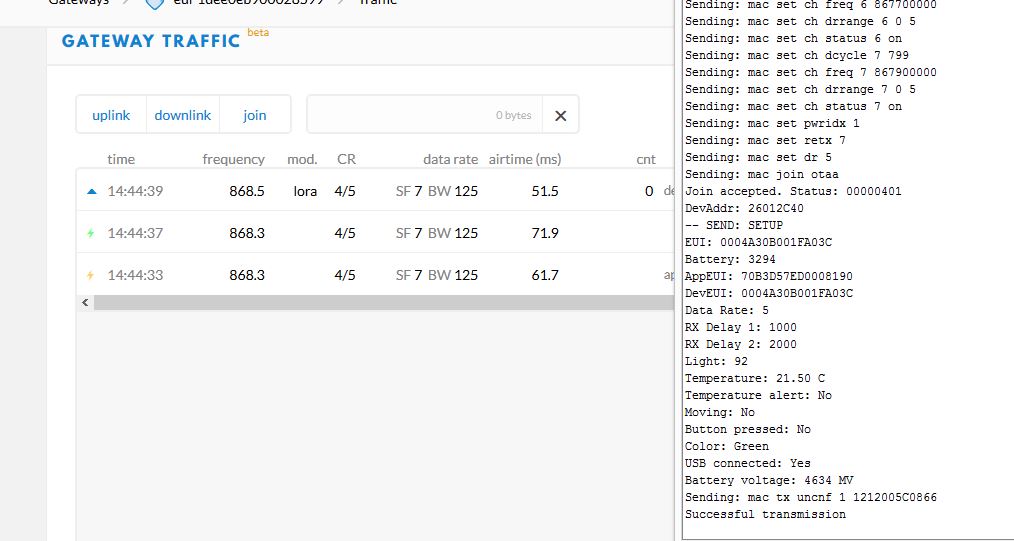
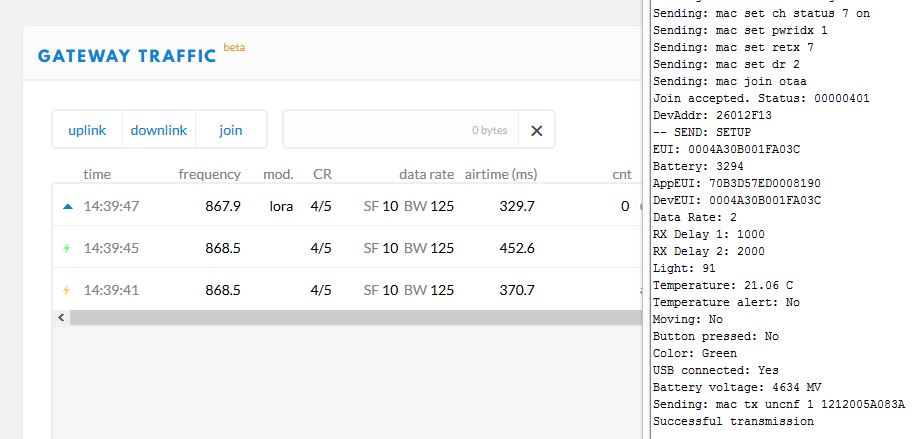
Starting from SF7 to 10 included, both the Join Request and Accept are always with the SF set up by the above instruction.
These are the output of the TTN gateway console and the Things Node debug console:
…
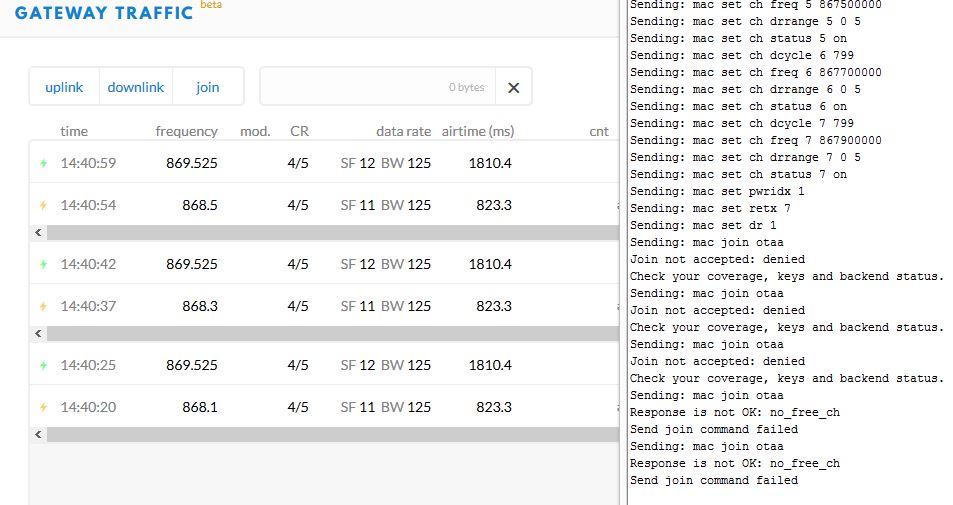
but if I set SF to 11 or 12, the Join Accept answer is always with SF12
For these two last conditions with SF11 and 12, the node try 3 times to join without any success and then try to send messagge but of course it was not able to.
I don’t know the detail of the lorawan at this level, it’s normal this behaviour in your opinion ?
Thanks,
Gianluigi
P.S.
One more think that seems confirmed is that both Things Node and another type of adr functioning node set the first uplink with counter 0, while the four nodes that give adr problems start with cnt 1.
Many thanks Jac,
so I think that testing with “The THings Node” doesn’t help me so much to identify the problem I have with ADR in the chain that includes TTN, Lorank8 gateway and the 4 SensingLab node of the same type.
So, I’m now trying another way.
I changed the packet forwarder in the lorank8 gateway to “Loriot” in order to test how these SensingLab nodes operate with this configuration.
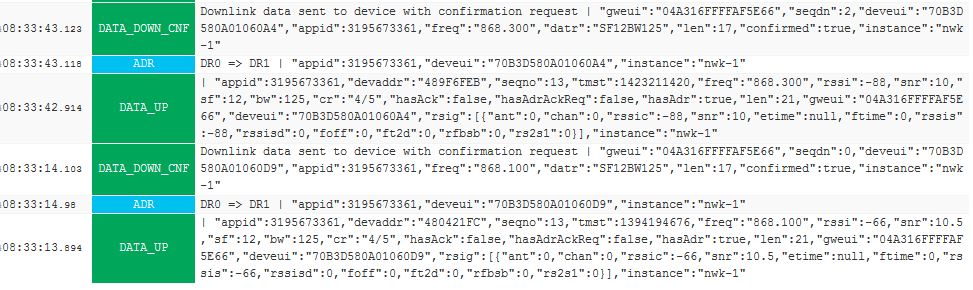
I switched off and on two of this nodes and after 13 uplink, they finally changed from SF12 to SF11 …
The online Loriot log shows these events:
I’m also attaching the lorank8 gateway daemon,log section related to the above events.
I didn’t find the events related to the second node (08:33:42 above) in this log file, but the first one (08:33:14) is reported. gw-log-loriot-pkt-fwd.txt (6.2 KB)
So it seems that the solution “Loriot+Loriot pkt-fwd” gives some ADR positive results for these nodes type.
I see in the forum some discussion about the poly pkt-fwd, it could be useful to test the original Semtech one ?
Very much agreed, very confusing… I think the same would apply to trying different packet forwarders on the same network. I feel we already established that TTN does send the ADR commands, in RX2, on SF9, which works for some node(s), but:
Can you repeat this behavior (so: TTN sending an ADR downlink in RX2/SF9, that specific node consistently not changing its settings, TTN re-trying in RX2/SF12 which the node should not receive to start with) if you decode some more uplinks/downlinks? Or did that happen only once?
To ensure TTN does not use old ADR statistics, this might require you to re-register all nodes in TTN Console as maybe TTN preserves the statistics for a new OTAA Join. I’ve no idea; we could peek into the code. Or maybe just temporarily changing the AppKey will clear the statistics, like it clears the DevNonce then. Registration and temporarily changing the AppKey could be automated using the command line ttnctl.
What does this mean? Does that make them lose all their state? (Given the low frame counters, I assume they do.) Or does this only imply that they’ve not been sending for some time? For ADR, TTN doesn’t care how often a node sends; it cannot know if a node is just sleeping, or has been switched off. Unless, of course, the node’s internal state is lost. Like: does it re-join after a power cycle? Does it start at a specific SF after restarting?
But so does TTN, right, for some but not all nodes?
If one node is having problems then it seems to me the nodes are just not 100% the same. Different software, different radio module (RN2xx3?), different firmware in that radio module. Just return the faulty one?
Thanks Arjan,
in order to contains the confusion, I try to summarize the current situation:
First of all, some preliminary clarifications:
For “switched off and on” a SensingLab node, I mean deactivate and reactivate the node using a magnet.
When I activate the node, it joins the network, mantaining the SF it has before the deactivation.
All the below test are carried out starting by a dectivations/activation of the nodes.
In the below test description the gateway is always Lorank8 using one of the two pkt-fwd (poly or Loriiot) as specified.
For simplicity let’s consider two test scenarios, both related only to the SensingLab nodes:
TTN server - Lorank8 (poly-pkt) - 4 nodes
3 SensingLab node are always on SF12 even if TTN shows on the console the ADR cmd
1 SensingLab node (1060bd) changed its SF, but this happened only 2 times over dozen of test
Loriot server - Lorank8 (Loriot pkt-fwd) - only 2 of the 4 avalaible nodes
The test was carried out using only two of the SensingLab nodes (those two nodes was choseed between the set of three that had problems with ADR in the above configuration with TTN server)
Both nodes lower their initial SF12 to SF11 as a consequence of the command the Loriot server sent to the Lorank gateway after 13 uplink.
Deactivation of the 3 SensingLab nodes (with magnet)
TTN deregistration of the 3 nodes (delete device)
New registration of the three nodes with AppKey different from the previous one, that is automatically created by TTN
Change of AppKey to match the one specified by SensingLab (without this the node doesn’t join)
Activation of the three nodes
Downlink cmd for changes reporting time (5 min)
logging of downlink msg by mqtt
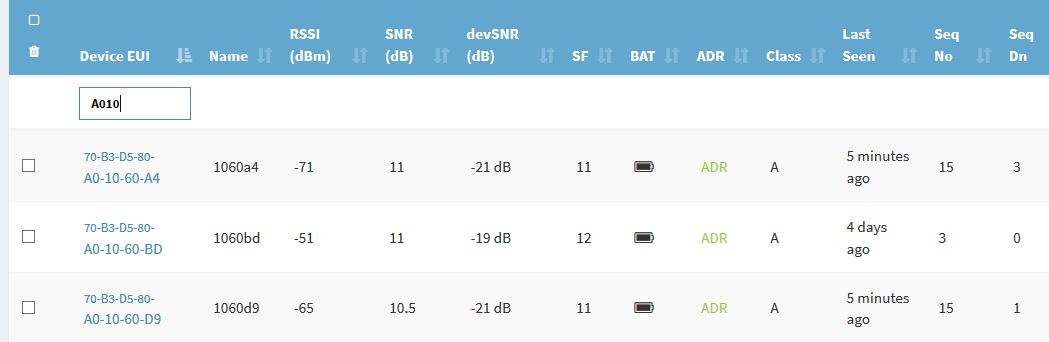
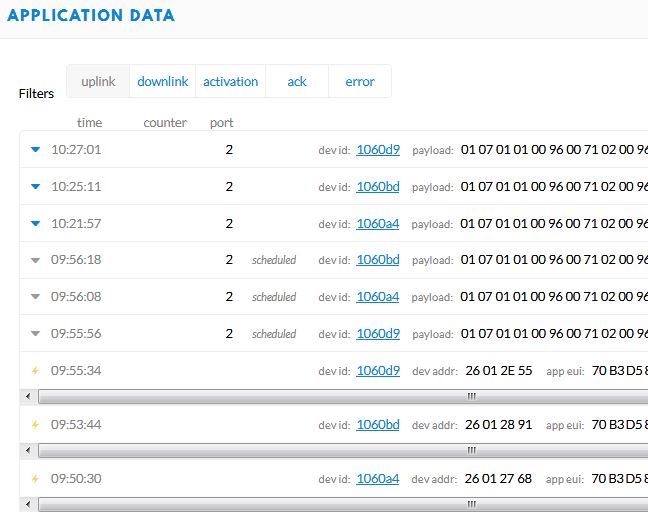
Here is a screenshot of the join and initial downlink cmd msg
I’ll wait for a minimun of 64 uplink to check if TTN will send a downlink with ADR.
Here are some additional information about the test:
One of the nodes (1060d9) didn’t receive the command for changing the uplink interval time reported in the above picture, so it was sent again some hour later.
For this reason this 1060d9 node have less uplink msg than the other two (1060bd and 1060A4) in the attached log file. senlab-t-up.txt (385.6 KB)
Looking at the attached downlink log, the 3 tested nodes starting from Feb 26th didn’t received any adr command and till now they have a SF12.
In the downlink log are instead reported some cmd on port 0 related to date/time before the test starting date (Feb-26). senlab-t-down.txt (372.7 KB)
Also a fourth node (1060c1), that is operating in another site and for this reason wasn’t resetted, received a downlink on the port 0 this morning .
So it seems that TTN doesn’t send no more mac adr command to these 3 nodes even if they were resetted and deregistred/ registered again.
It would be useful to have in the TTN console a flag that classify a node as a let’s say “adr banned”.
After the above post and a lot of uplink (more than 200), TTN sent a downlink msg on port 0 to all the 3 nodes in a 5 minutes time window (08:54 to 08:59).
It’s difficult to me to understand the logic of these downlink msg, they were send at the same time to all the nodes, even if they have different uplink counters.
Here are the updated log files. senlab-t-up.txt (425.2 KB) senlab-t-down.txt (373.6 KB)
Hello,
From our side, and after check of the LoRaWan specs, we confirm there is a problem with the default RX2 (for EU): That must be 869.525MHz / DR0 (SF12, 125kHz) but, TTN RX2 default is: 869.5250 MHz / DR3 (SF9, 125kHz)
Because that, ADR is not working with LoRaWan devices that are fully compliant with the LoRaWan spec.
ADR works perfectly with Sensing-Labs devices on others LoRaWan networks (operated network or local gateway), because RX2 is on 869.525MHz / DR0 (SF12, 125kHz).
We suggest 2 possibilities for TTN:
update the RX2 to today LoRaWan specs (869.525MHz / DR0 (SF12, 125kHz)
OR
send mac command to RX1 (the same SF of the device)
LoRaWAN providers are allowed to change the RX2 frequency and spreading factor (Check LoRaWAN specification chapter 3.3.2 second sentence). Anyone using OTA will receive the correct values during the join cycle. All ABP devices (a mode that is insecure and should not be used anyway) have to program the correct RX2 settings themselves.
LoRaWAN providers are allowed to change the RX2 frequency and spreading factor (Check LoRaWAN specification chapter 3.3.2 second sentence). Anyone using OTA will receive the correct values during the join cycle. All ABP devices (a mode that is insecure and should not be used anyway) have to program the correct RX2 settings themselves.
Yes, the operator can change the RX2, but the default RX2 must be DR0 (see LoRa spec extract bellow).
Using the default RX2, the network can change it to another DR.
In your document, they don’t talk about default for RX2, but hardcoded default SF12.
Sensing-Labs devices start at SF12, but can switch to another SF when asked from the network wih ADR MAC command, following the LoRaWan spec. I agree that the ADR mechanism is managed by the network (TTN for example).
For an OTAA Join Accept, TTN will use the default SF12 (DR0) when using RX2.
For EU868, in that Join Accept’s CFList, it will change the settings to use SF9 for RX2.
For US915 and AU915, for which LoRaWAN 1.0.2 does not support such CFList in the Join Accept, TTN will send an “initial ADR” with similar settings, after the first uplink; I assume it’s also using the defaults for that when using RX2, but I’ve not validated.
When a node keeps using the same settings if ADR was sent using RX2/SF9, then TTN assumes that the node has the incorrect RX2 settings, and repeats the ADR in RX2/SF12, meanwhile also telling it about the RX2 settings.
As @arjanvanb already mentions, TTN does follow that spec with regard to the defaults as long as a node uses OTAA, which it should anyway because ADR with fixed keys is a security risk.
With regards to using SF12 as a starting point, even with ADR a significant amount of SF12 traffic is required for the network to determine what a node can be switched to safely. Using SF12 as a starting point also means (given the TTN fair access policy) not a lot of uplinks are allowed before the allowed 30 seconds a day are exhausted, so a node may have to wait days before sufficient uplinks are available for ADR to kick in. Perhaps you should consider making the starting spreading factor configurable to the user?
From the point of view of a user that doesn’t know so much details of the Lorawan specification, I’ have a couple of questions.
Does the optional CFList field in the join must necessarily be considered by an end node or it’s optional ?
What happens if an end node is able to communicate with SF10 and SF11, but not with SF9 ? Will it able to receive the ADR command from the server ?
More in general, I observe that different point of view of a certified end node manufacturer and a network operator on the ADR management, currently determines a critical situation both in terms of energy consumption of the final node and SF12 network traffic.
Gianluigi
The specifications are not that hard to read; I’d say a compliant device needs to adhere to the settings:
If present, the CFList replaces all the previous channels stored in the end-device apart from the three default channels. The newly defined channels are immediately enabled and usable by the end-device for communication.
For ADR, a device should respond with a LinkADRAns (in its next uplink), telling the server which settings it accepted.
For RX2/SF9, TTN uses a higher transmit power for the downlink. So, hopefully the gateway supports that, and adheres to that:
As an aside: I don’t understand why @lopic34 might think the problem at hand is caused by using RX2/SF9. TTN repeats the ADR in RX2/SF12, just as a courtesy. But somehow neither SF9 nor SF12 are received, or not processed. So I’d guess the SF9 should not be the issue (though I feel it should listen to SF9 for RX2)?
Also, it seems different devices show different behaviour? (I’ve not peeked in the log files, nor have read the recent posts very well, but the topic’s title seems clear to me.)
being a member of the Sensing Labs team and seeing the issues experienced by gigi130358, I passed some time to understand exactly what happens with ADR on TTN network with Sensing Labs devices.
My starting point was : “I am sure ADR works fine on Sensing Labs devices” as they have already been certified by LoRa Alliance testing house for years now and successfully passed interoperability extensive tests with several operators.
What I did is quite simple: connect a device on TTN network through a local gateway and see what happens while directly debugging the node. With this method, I have been able to check the following items:
the SF9 configuration of RX2 window configured through the Join Accept is taken into account by the devide
sending application level downlink messages works on RX1 and RX2 windows
after between 50 to 100 uplink frames, the network had not yet sent any ADR request as we can check on gateway console or with downlink counters
From this step, I could conclude there was no particular issue on the device: it was not switching its datarate because it was not requested to by the network. But why?
From the LoRaWAN specifications, it is specified that a device configured for transmitting with its lower datarate (DR0 or SF12 in the case of Sensing Labs devices) never sets the ADRAckReq bit. As the device starts in SF12 by default, that means that it will never set its ADRAckReq bit unless the network first changes its datarate.
Looking at the ADR documentation for TTN (https://www.thethingsnetwork.org/docs/lorawan/adr.html), I found that there where several conditions that can trigger an ADR request from the network (3 in our case as these are EU868 devices):
enough measurements and datarate is not optimal: ADR request is scheduled for being piggy-backed with the next downlink (“optimize” tag)
enough measurements and the device is using DR0 --> it seems to be the case here
ADRAckReq bit set by the device which cannot happen here as the device is configured in DR0
However, the status is that the device does not receive any ADR request from the network.
I thus modified the device behavior for allowing it to set the ADRAckReq bit even if configured in DR0 and in this case it received and accepted successfully the ADR request from the network. However this tricky behavior does not respect the LoRaWAN specifications and should not be considered as THE solution to this issue.
What I need to understand now is:
what does “enough measurements” mean?
why the second condition does not trigger the transmission of an ADR request from the network (“enough measurements and the device is using DR0”)?
I hope these experiments will help solving the issue but I think I need help from TTN side now for going further.
The ADRACKReq shall not be set if the device uses its lowest available data rate because in that case no action can be taken to improve the link range.
So it seems that the server indeed needs to initiate ADR downlinks, regardless if it’s seeing an ADRACKReq. @htdvisser?
The ADRACKReq SHALL not be set if the device uses its default data rate and transmit power because in that case no action can be taken to improve the link range.
Concerning the change between 1.0.3 and 1.1, I believe this is only for ensuring that a device does not lock in a configuration where the used datarate is DR0 but transmit power is not configured to the maximum.
Until there, I have not yet seen ADR algorithms putting devices in such a state (usually, transmit power is only reduced when the device is using SF7 or higher datarates if available), but specifications need to be generic.
The problem is now resolved
TTN team corrected the ADR process and updated the network.
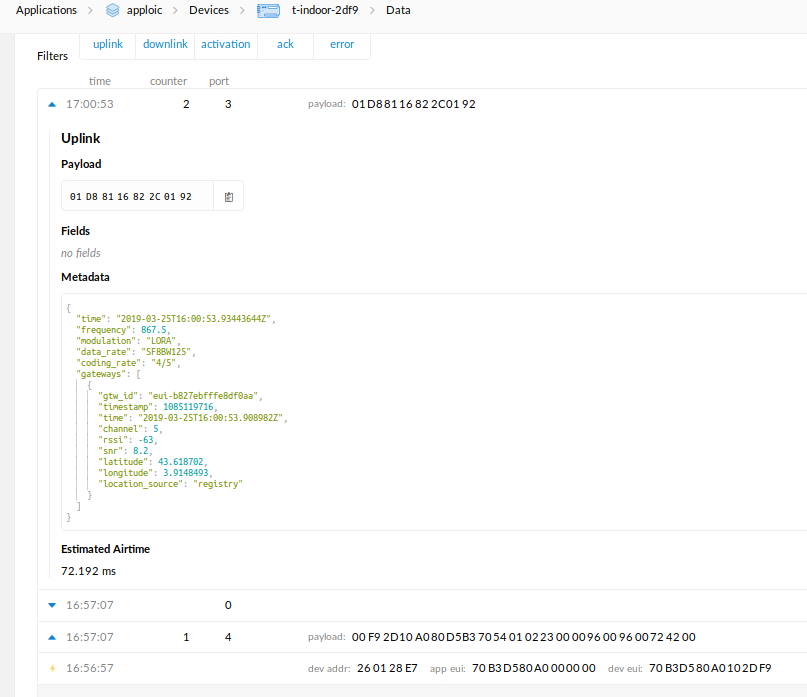
We just tried on our gateway and the sensing-Lab device successfully turned to SF8, after been activated on SF12 (see picture bellow).
Thank to gigi130358Gianluigi for posted this issue and nicolas_dejean_sensi for explain and forward it to TTN team.